
通过语法数据扩增提升推理启发法的鲁棒性
摘要
诸如BERT的预训练的神经模型在微调以执行自然语言推理(NLI)时,常常在标准数据集上展现出了高度准确性,但在受控的挑战集上,它们却表现出对语序敏感度的出奇缺乏。我们假设此问题并不主要因为预训练模型的局限性引起,而是由于缺乏众包的NLI样例引起的,而这些样例可能在微调阶段传递了语法结构的重要性。我们探索了几种方法来扩增标准训练集中语法丰富的实例,这些实例是通过对MNLI语料库的句子应用语法转换而生成的。而表现最好的扩增方法,主语/宾语倒置法,可以在不影响BERT对MNLI测试集性能的情况下,将BERT对受控实例的词序敏感度诊断从0.28提升至0.73。这种改进全面超过了用于数据扩增的特定结构,这表明了扩增可以使BERT学习到抽象语法的表现形式。
1. 介绍
在NLP里常见的监督学习范例中,特定分类任务的大量标记实例被随机地分为训练集和测试集。系统在训练集上进行训练,然后在测试集上进行评估。神经网络,尤其是对单词预测对象的进行预训练的系统,如ELMo(Peters et al.,2018)或BERT(Devlin et al.,2019)——在这种范例中表现出色:在具有足够大的预训练语料库的情况下,这些模型在许多测试集上所表现出的准确性达到甚至超过了未经训练的人类标注者(Raffel et al.,2019)。
同时,越来越多的证据表明,从与训练集相同的范围中提取的测试集上的高精度并不表示模型已经掌握了该任务。当模型应用于表示相同任务的不同数据集中,这种差异可能表现为准确性的急剧下降(Talmor and Berant, 2019;Yogatama et al., 2019),或者表现为对输入语言无关扰动的过度敏感(Jia and Liang, 2017; Wallace et al., 2019)。
在自然语言推理(NLI)任务中,McCoy等人(2019b)记录了这样的一种差异,即模型在标准测试集上的出色性能并不对应表明它能像人类定义的那样精通于此任务。在这个任务中,系统将获得两个句子,其被期望确定一个句子(前提)是否蕴含另一个句子(假设)。即使不是所有人,大多数人也都会同意NLI需要对语法结构敏感。例如,以下句子即使包含了相同的单词,但它们并不相互蕴含:
(1) 演员看到了律师 (The lawyer saw the actor.)
(2) 律师看到了演员 (The actor saw the lawyer.)
McCoy等人构造了HANS挑战集,其包含了一系列此类构造的例子,并且其被用来表明,当BERT在MNLI语料库进行微调时,该微调模型在从该语料库提取的测试集上取得了较高的准确率,但其对语法几乎没有敏感性;该模型会错误地得出结论,如(1)蕴含(2)。
我们考虑用两种解释来说明为什么在MNLI上微调的BERT会在HANS上失败。在代表性不足假设下,BERT在HANS上失败,是因为它的预训练表现形式缺失了一些必要的语法信息。而在缺失连接的假设下,BERT从输入中提取相关语法信息(参见 Goldberg 2019;Tenney et al. 2019),但是它无法在HANS上使用这个信息,因为很少有MNLI训练实例可以表明语法应该如何支持NLI的(McCoy et al., 2019b)。这两种假设都有可能是正确的:部分语法方面BERT可能根本未学习到,还有部分方面已经学过了,但并没有应用被用于进行推理。
缺失连接假设预测,从一个语法结构中使用少量的实例进行训练集的扩增将使BERT知道任务需要它使用它的语法表现形式。这不仅将使得用于数据扩增的结构的改进,并且也可推广到其他结构上。相反,代表性不足假设预测,模型想要在HANS上具有更好的表现,BERT必须从头开始学习每种语法结构是如何影响NLI的。这预计需要有更大的数据扩增集来获得足够的性能,并且整个结构几乎不能泛化。
本文旨在验证这些假设。我们通过对MNLI的少量实例进行语法转换以构造扩增集。尽管在MNLI上只扩增了约400个主语与宾语互换的实例(大约是MNLI训练集大小的0.1%),但模型对语法上具有挑战性的案例的准确率得到了显著的提高。更关键的是,即使在扩增中仅使用了一个单一的变换,但在一系列的结构中,准确度都得到了提高。例如,BERT在涉及关系从句的实例(例如,演员给游客看到的银行家打电话(The actors called the banker who the tourists saw) 无法推导出银行家打电话给游客(The banker called the tourists))在未扩增的实例中准确性为0.33,而扩增后为0.83。这表明我们的方法并不会过度适应于一个结构,而是利用了BERT现有的语法表示形式,从而为缺失连接假设提供了支持。同时,我们还观察到了泛化的局限性,在这些情况下,它们支持了代表性不足的假设。
2. 背景
HANS是一个模板生成的挑战集,旨在测试NLI模型是否采用了三种语法启发法。首先是词汇重叠启发法,其假定所有时间内所有在假设中的单词也都在前提中,且标签需是蕴含标签。在MNLI训练集中,这种启发法通常会做出正确的预测,几乎从不做出错误的预测。这可能是由于MNLI生成的过程所致:众包工作者被给予一个前提,并被要求生成与该前提相矛盾,或是蕴含这个前提的句子。为了最大程度地减少工作量,工作人员可能过度地使用了词汇重叠,将其作为一种生成含义假设的捷径。当然,词汇重叠启发法并不是一种普遍有效的推理策略,并且在许多HANS实例中都是失败的。例如上文所述,律师看到了演员(the lawyer saw the actor),并不意味着演员看到了律师(the actor saw the lawyer)。
HANS还包括诊断子序列启发法(假定前提蕴含任何与其相邻的子序列的假设)和成分启发法(假设前提蕴含其自身所有构成要素)的实例情形。当我们专注于对抗词汇重叠启发法时,我们还将测试其他启发法的泛化情况,这可以看作是词汇重叠中特别具有挑战性的案例。表A.5,A.6,A.7给出了用于诊断这三种启发法的所有结构的实例。
数据扩增通常用于增强视觉的鲁棒性(Perez and Wang, 2017)与语言的鲁棒性(Belinkov and Bisk, 2018; Wei and Zou, 2019),包括了NLI (Minervini and Riedel, 2018; Yanaka et al., 2019)。在许多情况下,使用一种实例进行扩增可以提高特定情况下的准确性,但不能泛化到其他情况,这表明模型过拟合于扩增集(Jia and Liang, 2017; Ribeiro et al., 2018; Iyyer et al., 2018; Liu et al., 2019)。特别的,McCoy等人(2019b)发现,HANS的实例的扩增可以泛化推广到不同的单词重叠挑战集(Dasgupta et al., 2018),但这仅适用于长度与HANS实例相似的实例。我们通过生成各种基于语料库的实例来减轻对表面属性的过度拟合,这些实例与挑战集上的词法与语法均不同。最后,Kim等人(2018)使用了与我们相似的数据扩增方法,但没有研究对不在扩增集中的实例类型的泛化。
3. 生成扩增数据
我们使用两种语法转换从MNLI生成扩增实例:倒置INVERSION(互换原句的主语与宾语)和被动化PASSIVIZATION。对于每个转换,我们都有两个系列的扩增集。原始前提(ORIGINAL PREMISE)策略保留了原有的MNLI前提,并对假设进行了转换;转换假设(TRANSFORMED HYPOTHESIS)使用原始MNLI假设作为新前提,转换后的假设作为新假设(实例见表1,具体请参见§A.2)。我们尝试了三种扩增集的大小:小型(101个实例),中型(405个实例),大型(1215个实例)。所有的扩增集都比MNLI训练集(297k)小得多。

我们没有试图确保生成实例的自然性;例如,在倒置转换中,车厢造成了大量噪音(The carriage made a lot of noise)被转换成大量噪音造成了车厢(A lot of noise made the carriage)。此外,扩增数据集的标签存在一些噪音;例如,我们假设倒置将正确的标签从蕴含改为中性,但是也并非必然如此(如果买方遇到卖方(The buyer met the seller),那么卖方遇到买方(The seller met the buyer)是有可能的)。如下所示,这种噪声不会损害MNLI的准确性。
最后,我们包括一个随机的打乱条件,其中MNLI前提及其假设都被随机打乱。我们使用这个情况来测试语法上不知情的方法是否能教会这个模型:当忽略单词顺序时,就无法做出可靠的推论。
4. 试验设置
我们将每个扩增集分别添加到MNLI的训练集中,并对每个生成的训练集进行微调BERT的训练。微调的更多细节在附录A.1中。我们为扩增策略与扩增集大小的每种组合重复了五个随机种子的过程,但最成功的策略(倒置+转换假设(INVERSION+TRANSFORMED HYPOTHESIS))除外。且对于每个扩增的范围,均进行了15次运行。参照McCoy等人(2019b),在对HANS进行评估时,我们将模型产生的中性与矛盾标签合并为一个单一的非蕴含(non-entailment)标签。
对于原始前提(ORIGINAL PREMISE)与转换假设(TRANSFORMED HYPOTHESIS),我们尝试了分别使用每一种转换,并使用了包含倒置与被动化的数据集进行了实验。我们还分别对仅使用带有蕴含标签的被动化例子和仅使用带有非蕴含标签的被动化例子进行了单独的实验。作为基线,我们使用了100次在未进行数据扩增的MNLI上训练出的微调的BERT模型(McCoy et al., 2019a)。
我们会报告模型在HANS上的准确性和在MNLI的开发集上的准确性(MNLI测试集的标签不公开)。我们没有调整这个开发集的任何参数。我们下面讨论的所有比较都在p<0.01的水平上,比较结果都是十分显著的(基于双向t检验)。
5. 结果
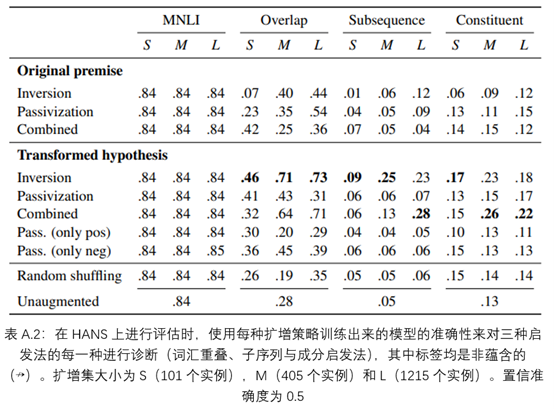
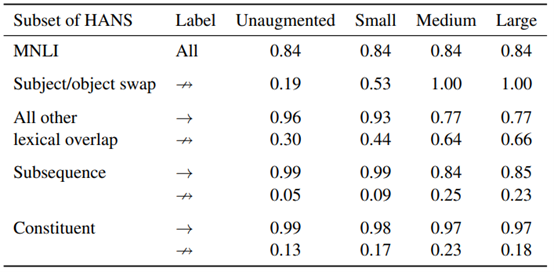
MNLI的准确性在不同的扩增策略中都非常相似,并且与未经扩增的基线(0.84)相匹配,这表明最多有1215个实例的语法扩增不会损害数据集的整体表现。相比之下,HANS的准确度差异很大,大多数模型在非蕴含的实例中的表现得比置信准确度差(在HANS上为0.5),这表明了它们采用了启发法(图1)。很大程度上,最有效的扩增策略是倒置结合转换假设。HANS在单词重叠案例(其中正确的标签都是非蕴含的,例如:医生看了律师(the doctor saw the lawyer)↛律师看了医生(the lawyer saw the doctor))的准确度在没有数据扩增的情况下为0.28,在大型扩增集上为0.73。同时,在启发法做出正确预测的情况下(如演员旁的游客们给作家们打电话(The tourists by the actor called the authors) → 游客们给作家们打电话(The tourists called the authors)),这种策略降低了BERT的准确性;实际上,在词汇重叠做出正确与不正确的预测情况下,最佳模型的准确度都是相似的,这表明了这种干预阻止了模型采用启发法。
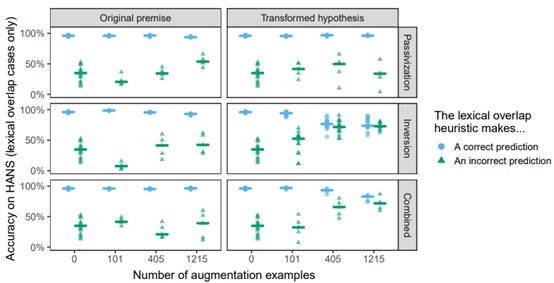
随机打乱的方法并未使模型在未经扩增的基线上得到了改善,表明关注语法的转换是必要的(表A.2)。被动化比倒置的收益要小得多,这可能是由于存在显式的标记引起的(如单词by),这可能导致模型仅在这些单词出现时才考虑词序。有趣的是,即使是在HANS的被动实例中,倒置也仍比被动化更有效(大型倒置扩增:0.13;大型被动化扩增:0.01)。最后,自身倒置比倒置与被动化的结合更有效。
现在,我们来更详细地分析最有效的策略,即倒置结合转换假设。首先,该策略在抽象层面上与HANS的主语/宾语交换类别相似,但是两者的词汇与语法特性均有不同。尽管存在这些差异,但模型在HANS类别上的表现在中型与大型扩增条件下都是完美的(1.00),这表明BERT能从转换的高级语法结构中受益。对于小的扩增集,此类别的准确性为0.53,表明有101个实例不足以使BERT知道不能随意的交换主语与宾语的对象。相反,将扩增大小从中型变至大型,能在HANS的子案例中产生适度且易变的效果(见附录A.3了解具体个案的结果);为了更清楚的了解扩增大小的影响,可能还需要对该参数进行更密集的采样。
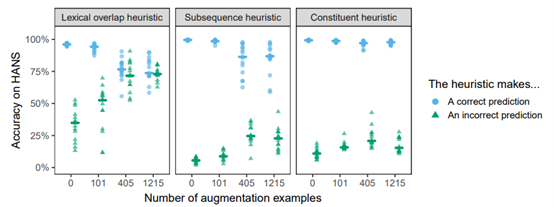
尽管倒置是该扩充集中的唯一转换,但是除了主语/宾语交换之外,其他结构的性能也得到了显著的提高(图2);例如,模型能够更好地处理包含介词短语的实例,例如,经理背后的法官看医生(The judge behind the manager saw the doctors)并不蕴含医生看经理(The doctors saw the manager),(未扩增:0.41;大型扩增:0.89)。在以子序列启发法方法为目标的案例中,有一个更平缓,但仍然十分明显的提升;这种较小程度的提升表明,对连续子序列从词汇重叠中分离处理更具泛化性。一个例外是对“NP/S”推论的准确性,例如经理们听说秘书辞职了(the managers heard the secretary resigned) ↛经理们听见了秘书说话(The managers heard the secretary),这一准确度从0.02(未扩增)大幅提升至0.5(大型扩增)。因此,对子序列案例的进一步改进可能需要涉及子序列的数据扩增。
在过去的一年中,人们提出了一系列技术来提高HANS的性能。这些模型包括语法感知模型(Moradshahi et al., 2019; Pang et al., 2019),旨在捕获预定义浅层启发法的辅助模型,以使主模型可以专注于稳健策略(Clark et al., 2019; He et al., 2019; Mahabadi and Henderson, 2019)以及提高难度训练实例权重的方法(Yaghoobzadeh et al., 2019)。尽管其中的一些方法在HANS上比我们的方法具有更高的准确性,包括更好的泛化了成分和子序列的情况(参见表A.4),但它们并不具有直接的可比性:我们的目标是在不修改模型或训练程序的情况下,评估训练集中的具有语法挑战性的实例是如何影响BERT的NLI的表现的。
6. 讨论
我们最佳效果的策略涉及通过对MNLI实例的主语/宾语倒置转换而生成的少量MNLI实例来扩增MNLI训练集。这产生了可观的泛化能力:既是对另一个域而言的(HANS挑战集),更重要的是,其也适用于其他结构,如关系从句和介词短语。这支持了缺失连接假设:对一个结构进行少量扩增会引起抽象的语法敏感性,而不是仅仅通过为模型建立来自同一分布的案例样本来“接种(inoculating)”模型,以防止在挑战集上失败(Liu et al., 2019)。
同时,倒置转换并未完全抵消启发法,特别是,这些模型在被动句上的表现较差。因此,对于这些结构,BERT的预训练可能在通过一个较小的扩增后,也仍无法产生强有力的语法表现形式;换句话说,这可能是我们的代表性不足假设成立的情况。该假设预测,作为单词预测模型的预训练BERT对于被动词处理困难,并且可能需要专门针对NLI任务学习其对应结构的特性;这可能需要大量的扩增实例。
表现最佳的扩增策略是从一个单独原句生成前提/假设对,这意味着该策略不依赖于NLI语料库。我们可以从任何语料库生成扩增实例,这使得我们有可能测试非常大的扩增集是否有效(当然,请注意,来自不同领域的扩增语句可能会影响在MNLI上本身的表现)。
最终,我们希望有一个能在跨语言理解任务中也能在使用语法方面具有强归纳偏差的模型,即使在重叠启发法导致其在训练集上的高精度时也是如此。事实上,很难想象人们在理解一个句子时会完全忽略语法。另一种可选的方法是创建足以代表各种语言现象的训练集;众包工作者(理性的人)偏爱使用尽可能简单的生成策略,这可以通过对抗性过滤等方法来抵消(Nie et al., 2019)。然而,在此期间,我们得出结论,数据扩增是一个简单而有效的策略,其可以缓解BERT等模型中已知的推理启发法。
A. 附录
A.1 微调细节
我们在所有实验中都使用了bert-base-uncased版本的模型。按照标准,我们通过在MNLI上训练线性分类器从CLS标记的最终层嵌入预测标签,同时继续更新BERT参数,来对该预训练模型进行微调(Devlin et al., 2019)。每个模型的训练实例顺序都进行了打乱。所有模型都经过了三个epoch的训练。
A.2 生成扩增实例
以下列表描述了我们使用的扩增策略。表A.1说明了应用于特定原句的所有策略。注意,倒置通常会改变句子的含义(侦探跟随着嫌疑犯(the detective followed the suspect)与嫌疑犯跟随着侦探(the suspect followed the detective)描述的并不是一个场景),但是被动语句并不会(侦探跟随着嫌疑犯(the detective followed the suspect)与嫌疑犯被侦探跟随(the suspect was followed by the detective)描述的是同一个场景)。
倒置(原始前提):对于原实例(p,h, →),生成(p,INV(h), ↛),其中INV返回主语与宾语调换了的原句,忽略原实例中标签为↛的实例。
倒置(转换假设):对于原实例(p,h) (带有任意标签),丢弃前提p并且生成(h,INV(h), ↛)
被动(原始前提):对于原实例(p,h) (带有任意标签),生成(p,PASS(h)),保持标签不变,其中PASS返回原句的被动语态版本(在不改变原意的情况下)
被动(转换假设):对于原实例(p,h),丢弃前提p,并且生成两个实例,一个携带蕴含标签——(h,PASS(h), →),一个携带非蕴含标签——(h,PASS(h), ↛)
我们使用MNLI提供的选区分析,识别出MNLI中可以作为原句的及物句,但噪声较大的TELEPHONE类型除外。为此,我们搜索了恰好带有VP的一个NP子节点的矩阵S节点,其中主宾都是完整的名词短语(即,都不是像me这样的人称代词),而动词词缀不是be或have。我们保留了动词的原始时态,并在必要时修改了他们的一致性特征。(如:电影是Matt Dillon和Gary Sinise 出演(the movie stars Matt Dillon and Gary Sinise)改为Matt Dillon和Gary Sinise 出演了这部电影(Matt Dillon and Gary Sinise star the movie))。
所有策略中,最大的扩增集大小为1215。这个大小是我们可以从MNLI生成的最大扩增数据集确定的,该数据集是使用了上述的倒置结合原始前提方法。为了公平比较,即使对于可以生成更大数据集的策略,我们仍保持相同的大小。我们还通过随机抽样405个使用上述过程识别的案例创造了中型数据集,以及包含了101个实例的小数据集。我们对于每种策略仅执行一次这个过程:因此,运行仅在分类器的权重初始化和实例顺序方面有所不同,而在训练中包含的扩增实例没有变化。
为了创建组合的扩增数据集,我们将倒置和被动化的数据集进行串联,然后随即丢掉一半实例(以使组合数据集的大小与其他数据集相匹配)。与其他数据集一样,我们只执行了一次:合并的扩增集在每次运行中相同。该过程的一个结果是,倒置和被动化的实例数量不完全相同。
A.3 详细结果
下列图表提供了我们试验的详细结果。
表A.2显示了每种策略在MNLI上的平均准确率,以及在诊断三种启发法(词汇重叠启发法,子序列启发法和成分启发法)中的每一种的HANS案例的平均准确率,正确的标签是非蕴含(↛)。表A.3探究了最佳扩增策略—具有转换假设的主宾倒置,包括了在正确的标签是蕴含(→)和非蕴含(↛)两种情况。
最后,末尾三个表格详细说明了通过倒置结合转换假设来对30个HANS子案例进行扩增的效果,并按设计按照诊断启发法来细分成表:词汇重叠启发法(表A.5);子序列启发法(表A.6)和成分启发法(表A.7)。

表A.1:语法扩充策略(完整表格)
表A.3:使用主语/宾语倒置结合转换假设的数据扩增对HANS准确性的影响。图表展示了在使用三种扩增集大小(101,405,1215个实例)来扩增的MNLI训练集后BERT的微调结果,也展示了在未经扩增的MNLI训练集上BERT的微调结果。
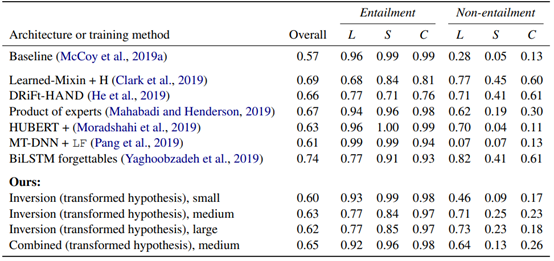
表A.4:不同的架构与训练方式所得到的HANS准确率,其被按照实例诊断的启发法与实例明确的标签拆分开来。除了MT-DNN+LF外,其余均采用了BERT作为基本模型。L,S与C分别代表词汇重叠、子序列和成分启发法。扩增集的大小为n=101(小型),n=405(中型),n=1215(大型)。
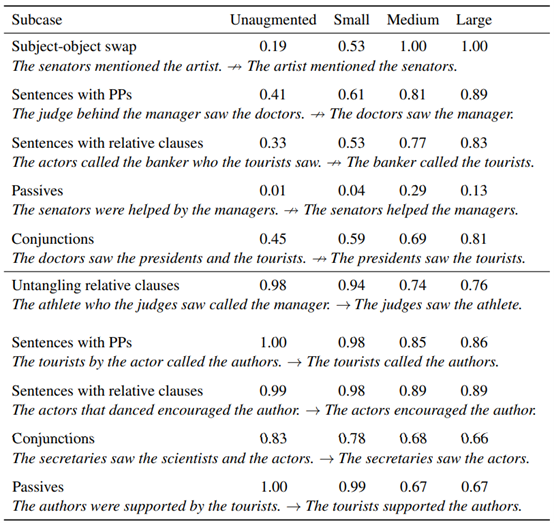
表A.5:主语/宾语倒置结合转换假设:图表展示了HANS子案例在诊断为词法重叠启发法时的结果,这些案例包括四种训练方案-未经扩增(只在MNLI上进行训练),和小型(n=101),中型(n=405),大型(n=1215)扩增集的情况。置信准确度为0.5。图表上半部分:标签是非蕴含的案例情况。图表下半部分:标签是蕴含的案例情况。
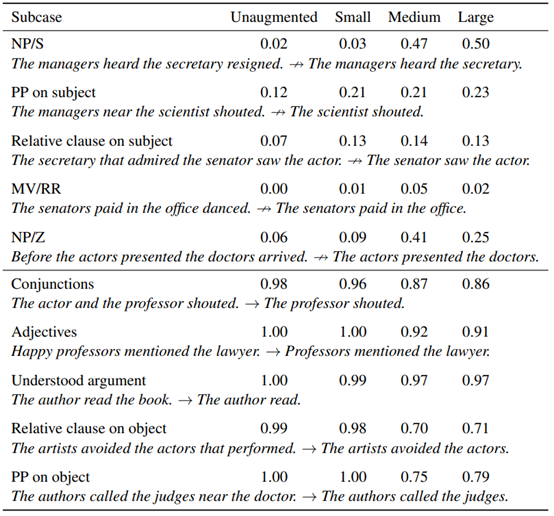
表A.6:主语/宾语倒置结合转换假设:图表展示了HANS子案例在诊断为子序列启发法时的结果,这些案例包括四种训练方案-未经扩增(只在MNLI上进行训练),和小型(n=101),中型(n=405),大型(n=1215)扩增集的情况。图表上半部分:标签是非蕴含的案例情况。图表下半部分:标签是蕴含的案例情况。
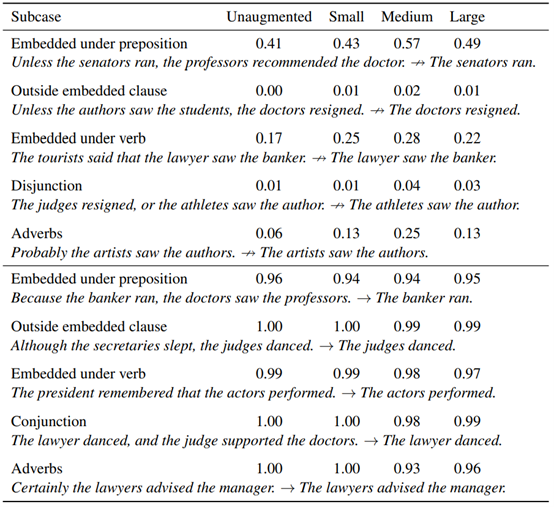
表A.7:主语/宾语倒置结合转换假设:图表展示了HANS子案例在诊断为成分启发法时的结果,这些案例包括四种训练方案-未经扩增(只在MNLI上进行训练),和小型(n=101),中型(n=405),大型(n=1215)扩增集的情况。置信准确度为0.5。图表上半部分:标签是非蕴含的案例情况。图表下半部分:标签是蕴含的案例情况。