
基于深度截图理解的众包测试报告优先级排序
摘要
众包测试在移动应用程序测试中日益占据主导地位,但对于应用开发者来说,审查数量过多的测试报告是很大的负担。已有许多学者提出基于文本和简单图片特征的测试报告处理方法。然而,在移动应用测试中,测试报告所包含的文本较为精简且信息不够充分,图片则能够提供更丰富的信息。这一趋势促使我们在深度截图理解的基础上,对众包测试报告的优先级进行排序。
本文中,我们提出了一种新的众包测试报告优先级排序方法,即DEEPPRIOR。我们首先引入一个新的特征来代表众包测试报告,即DEEPFEATURE,它基于对应用程序截图的深度分析,涵盖了所有组件(widget)及它们的文本、坐标、类型甚至是意图。DEEPFEATURE包括直接描述bug的bug特征(Bug Feature),和刻画bug完整上下文的上下文特征(Context Feature)。DEEPFEATURE的相似度用于表示测试报告的相似度,并被用于对众包测试报告进行优先级排序。我们形式上将相似度定义为DEEPSIMILARITY。我们还进行了一个实证实验,以评估所提技术在大型数据中的有效性。结果表明,DEEPPRIOR性能最佳,以不足一半的成本获得优于其它方法的结果。
索引词 众包测试,移动应用测试,深度截图理解
I. 介绍
众包已成为许多领域的主流技术之一。众包的开放性带来了许多优势。例如,可以在多个不同的实际环境中模拟对众包活动的操作。这样的优势有助于缓解移动应用(app)测试中严重的“碎片化问题”。成千上万种不同品牌、不同操作系统(OS)版本、不同硬件传感器就是安卓测试中众所周知的“碎片化问题”[1]。众包测试是解决这一问题的最佳方案之一。应用开发者可以将它们的应用程序分发给拥有不同移动设备的众包工人,并要求他们提交包含应用截图和文本描述的测试报告。这有助于应用开发者尽可能多的发现问题。
然而,众包测试的报告审查效率低是一个严重的问题。众包的开放性会导致有大量的报告被提交,而几乎82%的提交的报告都是重复的[2]。由于报告的复杂性,自动审查报告是一项艰巨的工作。在文字部分,自然语言的复杂性可能导致歧义,并且众包工人可能使用不同的词来描述相同的对象,或使用相同的词来描述不同的场景。在图像部分,由于许多应用使用相似的UI构建函数,截图的相似度也几乎没有帮助。因此,对于应用程序开发人员来说,及时发现报告中的bug是困难但重要的。
在近期的研究中,测试报告的处理通常分为两部分:应用截图和文本描述。现有的研究分别对这两部分进行分析以提取特征。对于文本描述,现有的方法是提取关键词,并根据预定义的词汇对关键词进行标准化处理。对于应用截图,它们将每个截图作为一个整体,提取用数字向量表示的图像特征。在获得了这两部分的结果之后,目前大多数的研究都以文本为依托,将截图作为补充材料,或者简单地将图像信息和文本信息进行拼接。然而,我们认为这样的处理方式会导致许多有价值的信息丢失。文本描述和应用截图之间的关系会被遗漏,报告的去重与确定优先级效果也可能更差。
在本文中,我们提出了一种新颖的方法,即DEEPPRIOR,通过对截图的深入理解来确定众包测试报告的优先级。DEEPPRIOR详细顾及了对应用截图和文本描述的深入理解。对于一份被提交的测试报告,我们会从截图和文本两者中提取信息。在截图中,我们通过计算机视觉(CV)技术收集所有widget,并根据文本描述定位问题widget(表示为WP)。其余的widget则被视为上下文widget(表示为WC)。本研究以自然语言处理(NLP)技术对文本进行处理,并分为两部分:复现步骤(以R表示)和bug描述(以P表示)。复现步骤被进一步标准化为“操作-对象”序列。bug描述也被进一步处理以提取对问题widget的描述,从而进行WP的定位。
我们不对应用截图和文本描述进行单独处理,而是将它们作为一个整体,并将所有信息收集起来作为报告的DEEPFEATURE。根据bug本身的关联性,DEEPFEATURE包括bug特征(Bug Feature,BFT)和上下文特征(Context Feature,CFT)。bug特征由WP和P组成,它表示报告中揭示的和bug直接相关的信息。上下文特征由WC和R组成,其代表的是上下文信息,包括触发bug的操作轨迹和bug发生时的activity的信息。
将上述特征整合到DEEPFEATURE中后,DEEPPRIOR将计算报告中的DEEPSIMILARITY以进行优先级排序。对于bug特征和上下文特征,我们分别计算DEEPSIMILARITY。
对于bug特征,为了计算报告中的WP的DEEPSIMILARITY,我们利用CV技术对特征点进行提取和匹配。P是一个简短的文本描述,因此我们使用NLP技术,在自建词汇表的基础上提取与bug有关的关键词,比较关键词的频率作为DEEPSIMILARITY。
对于上下文特征,WC被输入到一个预先训练好的深度学习分类器中,以识别每个widget的类型,每个类型的数字向量作为WC DEEPSIMILARITY。R由一系列操作和对应的widget组成,代表了从应用启动到bug发生的序列。因此,我们按照R的顺序,利用NLP技术提取操作和对象。我们将“操作-对象”序列作为行为轨迹,并计算DEEPSIMILARITY。
之后进行优先级排序。我们首先构建一个NULL 报告(如章节III-D中定义),并将其添加到优先级报告池中。之后,我们反复计算每个未确定优先级的报告和报告池中所有报告之间的DEEPSIMILARITY。具有与优先级报告池中相比最低的“最小DEEPSIMILARITY”的报告会被放入优先级报告池中。
我们还设计了一个实证实验,使用一个大型活跃的众包测试平台的大规模数据集组。我们将DEEPPRIOR与其他两种方法进行了比较,结果表明,DEEPPRIOR是有效的。
本文的重要贡献如下:
* 我们提出了一个新颖的方法,通过对截图的深入理解和详细的文本分析,对众包测试报告进行优先级排序。我们从截图中提取所有widget,将文本信息分类到不同的类别,并构建DEEPFEATURE。
* 我们构建了一个用于对截图进行深入理解的集成数据集组,包括大规模的widget图像数据集、大规模的测试报告关键词词汇、大规模的文本分类数据集和大规模的众包测试报告数据集。
* 基于数据集,我们对提出的方法DEEPPRIOR进行了实证评估,结果表明,DEEPPRIOR以不到一半的开销胜过了当前最新的方法。
II. 背景与动机
众包测试在移动应用测试中得到了广泛的应用,其优点是显而易见的,但其弊端也是不可忽视的。在大多数主流的众测平台上,众测工人都需要提交一份报告来描述自己所遇到的bug。报告的主题是对bug的截图和文本描述。应用的截图和文本描述也同样是对众测报告进行优先级排序的主要依据。
目前考虑截图的众测报告处理方案,如[2][3]主要是分析应用截图特征和文本描述信息来衡量所有报告之间的相似度。虽然他们考虑了应用截图,但只是将图片简单地处理为宽x高xRGB的矩阵。然而,这些方法忽略了丰富而有价值的信息,我们认为应该把应用截图看作是有意义的widget的集合,而非无意义的像素的集合。这是因为在回顾众测报告数据集的时候,我们发现了一些生动的例子,现有的方法难以处理它们,因为这些方法只是做了简单的特征提取,而没有对截图进行深度理解。
A. 样例1:不同的应用主题
现在的应用都支持不同的主题,用户可以根据自己的喜好定制应用的外观(图1)。此外,“深色模式”使得配色方案更加复杂。图像特征提取算法很难处理这样的复杂问题,会出现错误。从这些样本中我们可以发现,三份报告中的应用截图分别为蓝色、白色和绿色主题。这三份报告都是报告音乐资源文件加载失败的。然而,根据文献[2],图像颜色特征是报告替代的重要组成部分之一。不同颜色的应用截图将被识别为不同的截图。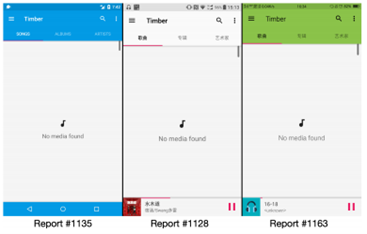
图1 样例1:不同的应用主题
B. 样例2:相同截图上的不同bug
如图2所示,两份报告使用的是相同的应用activity的截图,图像特征提取算法会在这两张截图之间给出一个较高的相似度。然而,根据bug描述,这两份报告描述的是完全不同的bug。在DEEPPRIOR中,对于报告#1128,我们可以提取出“未找到媒体”的文字;对于报告#1127,除了提示信息之外,我们还可以提取出音量widget,DEEPPRIOR可以识别出不同的问题。
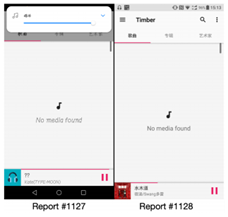
图2 样例2:相同截图上的不同bug
C. 样例3:不同截图上的相同bug
如图3所示,顶部的ImageView widget的内容不同,且其占据了整个页面的很大比例。并且,由于测试时间不同,评论也不同。因此,现有的方法会认为两张截图的相似度低,即使文本描述的相似度很高,也会降低整体相似度。而通过DEEPPRIOR,我们可以提取底部的弹出信息,为“发表评论失败”,并给两个报告分配一个很高的相似度。这样的弹窗被认为是相当重要的、包含bug的widget。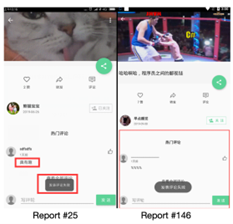
图3 样例3:不同截图上的相同bug
III. 方法
本节介绍DEEPPRIOR的详细内容,即通过深度截图理解,对众测报告进行优先级排序。DEEPPRIOR由4个阶段组成,包括特征提取、特征聚合、DEEPSIMILARITY的计算与报告优先级排序。我们从应用截图和文本描述两者中收集4种不同类型的报告特征。然后,我们将提取的特征汇总成一个DEEPFEATURE,其包括bug特征和上下文特征。基于DEEPFEATURE,我们设计了一个算法来计算每两份测试报告之间的DEEPSIMILARITY。基于预先定义的规则(详见章节III-D),我们根据DEEPSIMILARITY对测试报告进行优先级排序。DEEPPRIOR方法的总体框架可参考图4。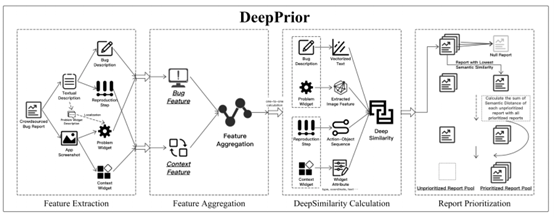
图4 DeepPrior框架
A. 特征提取
第一步也是最重要的一步,为特征提取。我们分别对众测报告的应用截图和文本描述进行分析。
\1) 应用截图中的特征。应用截图在众测报告中至关重要。众测人员需要在bug发生时进行截图,以便更好地阐述bug。如文献[2]所描述,文本描述仅能提供有限的信息,可能不足以清晰地描述bug。因此,除了文本描述之外,还要考虑截图来提供更多的信息。在一张截图中,存在许多不同的widget,有些widget可以提示bug信息。因此,对截图的深度理解主要依赖于widget。在DEEPPRIOR中,我们使用CV技术和深度学习(DL)技术来提取所有的widget并分析其信息。DL技术功能强大,CV技术可以处理更多种类的任务[4]。
问题widget。一个应用activity可以被看作是一个有组织的widget集。一般来说,在众测任务中,众测人员能够发现的bug都会通过widget显露出来。因此,找到引发bug的widget,并将这个widget与其他widget区分开来是很重要的,而该widget就是我们所定义的问题widget(WP)。为了区分问题widget,我们分析文本描述。在众测报告中,众测人员会指出在bug发生前操作了哪个widget。如章节III-A2所示,我们可以从文本描述中提取出问题widget,并且为了定位问题widget,我们针对不同的情况可采取两种不同的策略。
* 如果提取的widget包含文本,我们将widget的截图和文本描述中的文本进行匹配。被匹配的widget被认为是问题widget。
* 如果widget上没有文本或文本匹配失败,我们将提取的widget送入深度神经网络,以识别简单的widget意图。该深度神经网络是在Xiao等人[5]的研究基础上修改而来的。该模型通过卷积神经网络(CNN)将widget截图编码为特征向量。输出是使用循环神经网络(RNN)从特征向量解码而得的短文本片段,该短文本片段描述了widget意图。
上下文widget。除了问题widget以外,应用截图中展现的widget集还包含了更多组成上下文的widget,而它们对深度图像理解也是至关重要的。在早期的调查中,我们发现,即使问题widget、复现步骤(activity启动路径)和bug描述相同,应用的activity也可能全然不同(如章节II-C中的启发性样例)。在这个情况下,上下文widget对于识别差异而言十分重要。因此我们将其余的widget收集为上下文widget(WC)。对于每个上下文widget,我们将widget截图输入卷积神经网络,以识别其类型。每个类型由14维向量构成。
卷积神经网络能够识别14种不同类型的、最为广泛使用的widget,包括Button(BTN)、CheckBox(CHB)、CheckTextView(CTV)、EditText(EDT)、ImageButton(IMB)、ImageView(IMV)、ProgressBarHorizontal(PBH)、ProgressBarVertical(PBV)、RadioButton(RBU)、RatingBar(RBA)、SeekBar(SKB)、Switch(SWC)、Spinner(SPN)、TextView(TXV)。为了训练神经网络,我们收集了36573张均匀分布在这14种类型上的widget截图。训练集、验证集和测试集的比例为7:1:2,这是图像分类任务的常见做法。神经网络由多个卷积层、最大池化层和全连接层组成。采用AdaDelta算法作为优化器,模型采用categorical_crossentropy作为损失函数。
\2) 来自文本描述的特征。除了应用截图,文本描述可以更直观、更直接地提供bug信息。同时,文本描述也可以作为应用截图的正向补充。在DEEPPRIOR中,我们采用NLP技术,特别是DL算法,对测试报告中的文本描述进行处理。
在文本描述中,众测人员需要对截图中的bug进行描述,并提供复现步骤,即从应用启动到bug发生的操作顺序。然而,在大多数众测平台上,bug描述和复现步骤是混在一起的,并且由于专业能力不同,众包工人并不被要求遵循特定的模式[6]。因此,将bug描述与复现步骤区分开是很复杂的。为了解决这个问题,我们采用了TextCNN模型[7]。
TextCNN模型可以通过预先训练的词向量完成句子级分类任务。在将文本输入模型之前,我们对数据进行预处理。将测试报告的文本描述分割成句子,再使用jieba库将句子分割成单词,根据停顿词列表过滤掉停顿词。预处理后,我们将文本送入词向量层。在该层中,利用Word2Vec模型[8]将文本转化为128维的向量。之后,我们采用多个卷积层和最大池化层来提取文本特征。在最后一层,我们使用SoftMax激活函数,得到每个句子是bug描述还是复现步骤的概率。最后,我们将所有分类为bug描述或复现步骤的句子进行合并。为了训练TextCNN模型,我们构建了一个大规模的文本分类数据集,由2252个bug描述和2088个复现步骤组成。我们按照惯例,将训练集、验证集和测试集的比例设置为6:2:2。
bug描述。bug描述总是以短句的形式出现。因此,我们用一个向量来表示句子,其也用Word2Vec模型编码。大多数的bug描述都遵循某种特定的模式,如“对某些widget进行了某些操作,发生了某些非预期的行为”,所以即使具体的词语会有所不同,但提取这种特征仍是有效的。
另一个重要的过程是提取问题widget的描述,以帮助对问题widget进行定位。为了实现这一目标,我们采用基于HMM(Hidden Markov Model,隐马尔科夫模型)模型的文本分割算法[9],并在文本分割之后分析bug描述的各个部分的词性。然后,我们提取对象部分作为问题widget定位的依据,句子中这样的对象部分就是触发bug的widget。在获取对象之后,我们使用上文所述的策略对问题widget进行定位。
复现步骤。除了bug描述外,文本描述的另一个重要部分是复现步骤。复现步骤是一系列的操作,描述了用户从应用启动到bug发生的操作。对于分类到复现步骤的句子,我们按照报告中的初始顺序进行处理。我们使用相同的NLP算法进行文本分割,并对每个句子的每个文本段进行词性分析。然后,收集操作部分和对象部分,形成“操作-对象”对。然后,我们将“操作-对象”对连接成一个“操作-对象”序列。另外,除了操作词和对象,我们还为一些特定的操作添加一些补充信息。比如,假设有一个操作是键入操作,我们会添加输入内容作为补充信息,因为不同的测试输入可能导致不同的处理结果,使应用定向到不同的activity上。最后,经过形式化处理后,我们就可以从文本描述中获得复现步骤。
B. 特征聚合
在从应用截图和文本描述中获取所有特征后,我们将其汇总为两个特征类别。bug特征(Bug Feature, BFT)和上下文特征(Context Feature, CFT)。bug特征指的是众测报告中直接反映或描述bug的特征,而上下文特征是由bug出现时提供环境描述的特征聚合而成。
\1) bug特征(BFT):bug特征可以直接提供bug的信息。由于众测报告是由应用截图和文本描述组成,这两部分都包含了发生bug的关键信息。在应用截图中,我们提取了问题widget,是widget截图。DEEPPRIOR可以自动提取这样的信息。在文本描述中,bug描述部分直接描述了bug。因此,在平衡考虑应用截图和文本描述的情况下,我们将问题widget和bug描述汇总为bug特征。
\2) 上下文特征(CFT):上下文特征包括了为bug的发生构建完整上下文的特征。在应用截图中,上下文widget由问题widget以外的所有widget组成。在文本描述中,之所以考虑到复现步骤信息是因为其提供了从应用程序启动到bug发生时的完整操作路径,可以帮助识别两个测试报告的bug是否在同一个应用activity上。因此,将上下文widget和复现步骤汇总在一起,构成上下文特征。
\3) 特征聚合:借助bug特征和上下文特征,我们可以将众测报告中的应用截图和文本描述中所获得的所有特征聚合到最终的DEEPFEATURE中。我们并非直接将应用截图转化为简单的特征向量,而是对应用截图进行深度理解。同时,我们对应用截图和文本描述之间的结合也更加紧密。此外,我们将应用截图和文本描述作为一个整体,根据它们在bug反馈中的作用进行划分。bug特征非常重要,我们认为上下文特征在众包测试报告的优先级确定中也应起到至关重要的作用,bug相似度的计算很大程度上依赖于整个上下文。
C. DEEPSIMILARITY的计算
要对众测报告进行优先级排序,一个主要的步骤就是计算所有报告间的相似度。由于我们是第一个将深度截图理解引入到报告的优先级排序中的,我们将这个相似度命名为DEEPSIMILARITY。之前的研究[2][3]普遍采用合并不同特征的做法,我们分别计算不同特征的DEEPSIMILARITY,并为不同特征的结果分配不同的权重。形式化表达如下:
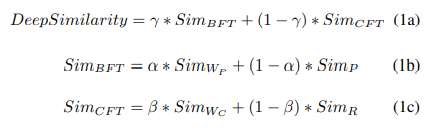
\1) bug特征:我们分别计算问题widget和bug描述的DEEPSIMILARITY,并使用参数α来整合他们。
问题widget。问题widget是根据章节III-A1中介绍的策略,从应用截图中提取的widget截图。为了计算问题widget的DEEPSIMILARITY,我们提取了widget截图的图像特征。为了提取图像特征,我们采用了最先进的SIFT(Scale-Invariant Feature Transform)算法[10]。因此,每个widget由一个特征点集来表示。SIFT算法的优点是可以处理不同尺寸、位置和旋转角度的图像,而这种图像在这样一个移动设备有成千上万种不同型号的时代是相当普遍的。为了对不同众测报告中的问题widget进行对比和匹配,我们使用FLANN库[11]。经过计算,我们可以得到一个0到1间的分数,0表示完全不同,1表示完全相同。这个分数可以看作是问题widget的DEEPSIMILARITY。
bug描述。bug描述是简短的语句,简要描述了众测报告中的bug。因此,我们使用NLP技术对bug描述进行编码。遵循以往研究中的方法,我们使用Word2Vec模型作为编码器。为了提高Word2Vec模型的性能,我们构建了一个测试报告关键词数据库。测试报告关键词 数据库包含了8647个与软件测试、移动应用、测试报告相关的关键词,包括了标注的同义词、反义词和多义词。编码后的bug描述是一个100维的向量。之后,仍参考前人的研究,如[2][3],我们采用广泛使用的欧氏度量算法来成对地计算不同测试报告中的bug描述的DEEPSIMILARITY。为了统一不同尺度的数值,我们使用函数 (x-min)/(max-min),以将每个结果x归一化到[0,1]区间,其中max是所有结果的最大值,min是所有结果的最小值。
\2) 上下文特征:我们还分别计算上下文widget和复现步骤的DEEPSIMILARITY,并使用参数β来整合他们。
上下文widget。上下文widget也是bug发生时整个上下文的重要组成部分。为了对应用截图有深度理解,特别是应用截图上的widget,我们使用卷积神经网络来识别每个提取的widget截图的widget类型,并形成一个包含14种widget类型数量的向量。之后,我们使用欧氏度量算法来计算获取的14维向量的距离。我们考虑了每个类型的widget的绝对数量和所有widget的分布情况。欧氏度量算法的结果(从0到1)即上下文widget的DEEPSIMILARITY。
复现步骤。在特征提取过程中,复现步骤被转化为“操作-对象”序列。为了计算“操作-对象”序列的DEEPSIMILARITY,我们采用动态时间规整(Dynamic Time Warping, DTW)算法处理待比较的“操作-对象”序列。DTW算法在自动语音识别方面表现出色。在本文中,我们调整了DTW算法来处理相应的众测报告中触发bug的操作路径。DTW算法可以测量时空序列的相似度,尤其是可能存在“速度”变化的时空序列。具体而言,我们任务中的“速度”是指不同的用户操作可以通过不同的路径到达同一个应用activity的情况。与其他轨迹相似度算法相比,DTW由于可以处理不同长度的序列,所以匹配的效果更好,适合处理“操作-对象”序列。
D. 报告的优先次序
在聚合了DEEPFEATURE,并定义了DEEPSIMILARITY的计算规则后,我们开始对众测报告进行优先级排序。首先,我们构建两个空报告池:非优先级报告池和优先级报告池。所有的众测报告最初都会被放入非优先级报告池。
与[3]中采用的随机选择一个报告作为初始报告的策略不同,我们认为应该平等的对待所有报告,随机选择报告可能影响最终的优先级。因此,为了使优先级算法形式化、统一化,我们引入了NULL报告的概念,它也包含了四个特点。
* 问题widget:问题widget的截图本质上是一个三维矩阵,分别代表宽度、高度和三个颜色通道。因此,我们将问题widget构造为一个零矩阵。零矩阵的宽度和高度设置为所有实际众测报告的平均大小。直观地说,它是一个全黑的图像。
* bug描述:NULL报告的bug描述直接设置为空字符串,由于字符串长度为0,显然不包含任何单词,经过Word2Vec处理后,特征向量将是一个100维的全部为“0”的向量。
* 上下文widget:对于NULL报告的上下文widget,我们直接构造出代表数量为14种的不同类型widget的向量,并且所有元素均为0。这表示众包的应用截图上“没有”widget。
* 复现步骤:NULL报告的复现步骤也设置为空字符串,“操作-对象”序列的长度也为0。
优先级划分的主要共识是,在某些报告会重复描述bug的情况下,尽早发现所有的bug[3][13][14]。
因此,要尽早为开发者提供尽可能多的描述不同bug的报告。基于这一思想,我们设计了如下的优先级策略,形式化表达式见算法1。

首先,我们根据上述规则构建NULL报告,并将NULL报告追加到空的优先级报告池中。接下来进行一个迭代的过程。我们计算每个未确定优先级的报告与整个优先级报告池的DEEPSIMILARITY,此DEEPSIMILARITY定义为未确定优先级的报告与优先级报告池中的所有报告的最小DEEPSIMILARITY。与优先级报告池中DEEPSIMILARITY最低的报告将被移至优先报告池中。
IV. 评估
A. 实验设置
为了评估我们提出的DEEPPRIOR,我们设计了一个实证实验。为了完成实验,我们收集了10个不同移动应用的536份众包测试报告(详见表I)。A1到A10代表10个应用,不同应用的测试报告数量在10到152之间。我们还邀请软件测试专家根据测试报告所描述的bug进行人工分类,平均一个bug类别的报告数量为8.06份。
表I 实验应用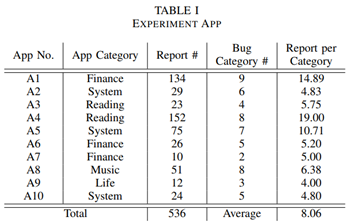
在众包测试报告数据集的基础上,我们建立了3个具体的数据集来更好地支持评估,包括1) 大规模widget图像数据集,2) 大规模测试报告关键词集,3) 大规模文本分类数据集。这4个数据集构成了综合数据集。
我们共设计了三个研究问题(RQ)来评估所提出的测试报告优先级确定方法DEEPPRIOR。
* RQ1:DEEPPRIOR如何有效识别从应用截图中提取的widget类型?
* RQ2:DEEPPRIOR对众测报告中的文本描述的分类效果如何?
* RQ3:DEEPPRIOR能多有效地确定众测报告的优先级?
B. RQ1:widget类型分类
第一个研究问题的设定是评估我们对应用截图的处理效果。在应用截图处理中,最重要的部分是widget的提取和分类。因此,我们评估了widget类型分类的CNN的准确性。我们共收集了36573张不同的widget图像,这些图像在14个类别中均匀分布。
CNN的具体介绍详见章节III-A1。数据集按惯例,按照7:2:1的比例划分为训练集、验证集和测试集。在CNN模型训练完成后,我们对测试集的准确性进行评估。widget类型分类的总体准确率达到89.98%。具体而言,我们用精确率(precision)、召回率(recall)和F值(F-Measure)评估网络。计算公式如下,其中TP表示真正例样本,FP表示假正例样本,TN表示真负例样本,FN表示假负例样本。
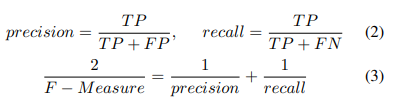
评估结果如表II所示,精确率平均值达90.05%,最低精确率为74.36%,最高为99.81%。对于衡量实际检索到的实例总量的召回率方面,平均值为89.98%,召回率值在70.83%至100%之间。F值是精确率和召回率的调和平均数,其平均值达到89.92%。以上结果反映了所提出的分类器的突出能力。
表II widget类型分类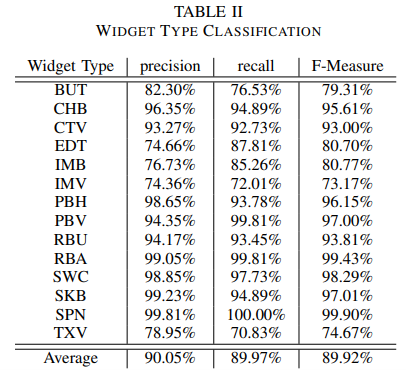
我们也对结果进行了深入的观察。我们发现,有两组widget容易被混淆。第一组包括ImageButton和ImageView。不难理解,从视觉上看,这两种类型几乎是无法识别的。这两种类型之间的唯一区别是,ImageButton可以触发一个操作,而ImageView只是一个简单的图像。不过,有一点很重要的是,在应用设计中,开发者可以在ImageView widget上添加一个超链接来实现等效的效果。第二组包括Button、EditText和TextView。这三个widget都是一个固定的区域,里面包含一个文本片段,从视觉上看也很相似,即使是人类也难以辨别。此外,一些特殊的渲染方式也让这些widget更加难以识别。根据我们的调查,我们发现这两组易混淆的widget不会有太大影响,无论是从视觉角度还是从功能角度,都可以把这些widget当作为等价的widget。
RQ1的结论:CNN对widget类型进行分类的总体准确率达到89.98%,对于每个具体类型,平均精确率达90.05%,最低精确率为74.36%,F值为89.92%。另外,根据我们对实测报告的调查,即使一些精确率较低的模型,其视觉和功能特征也不会对DEEPPRIOR造成负面影响。
C. RQ2:文本描述分类
在文本描述的处理中,我们将其分为两类:bug描述和复现步骤。不同的文本描述被认为是不同的报告特征。为了对文本描述进行分类,我们将文本描述分割成句子。然后,我们将这些句子输入到TextCNN模型中来完成任务,详细介绍参见章节III-A2。同时,为了更好地训练和评估网络,我们建立了一个大规模的文本分类数据集。该数据集包含了4340个标记的文本片段,其中包括2252个bug描述和2088个复现步骤。数据集按照7:2:1的比例分为训练集、验证集和测试集。
表III 文本分类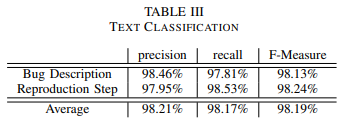
RQ2的结论:文本分类的整体准确率达到96.65%。精确率、召回率和F值都在98%以上。这样的结果显示了DEEPPRIOR对文本描述的优秀分析能力,这也为众测报告的优先级的排序打下了坚实的基础。
D. RQ3:众包测试报告的优先级排序
在本研究问题中,我们评估DEEPPRIOR的测试报告优先级排序效果。我们使用的指标是APFD(Average Percentage of Fault Detected)指标[15],Feng等人也使用该指标对众测报告进行优先级排序的评估[3]。在公式中,表示最先发现bugi的报告的索引,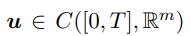 n是报告总数,M是暴露的bug的总数。
n是报告总数,M是暴露的bug的总数。
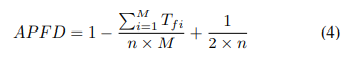
为了更好地说明DEEPPRIOR的优势,我们将DEEPPRIOR与以下优先级策略进行比较。
* IDEAL:这种策略理论上是具有最好的优先级排序,意味着开发人员可以在最短的时间内审查所有报告中的bug。
* IMAGE:这种策略只使用DEEPPRIOR的深度图像理解结果来对测试报告进行排序,因为深度图像理解是我们研究的重要组成部分。
* BDDIV:这种策略参考了Feng等的工作[3]的算法,这也是众包测试报告优先级排序的最先进的方法。
* RANDOM:RANDOM策略指的是没有任何优先级策略的情况。
对于DEEPPRIOR和IMAGE策略,因为我们的方法很稳定,所以我们运行一次,训练后的模型不会因为不同的尝试而产生不同的结果;对于IDEAL策略,我们手动计算APFD,因为对于固定的报告簇而言,它是一个定值;对于BDDIV策略,我们运行30次,然后像原文[3]一样计算平均值;对于RANDOM策略,我们运行100次,以消除偶然情况的影响。
首先,我们将DEEPPRIOR与RANDOM策略进行比较。如表IV所示,我们发现DEEPPRIOR策略比RANDOM策略效果好了许多,从15.15%至38.93%之间不等,并且平均提升幅度达27.04%。由此可见DEEPPRIOR的优越性。
表IV DEEPPRIOR报告优先级排序结果与比较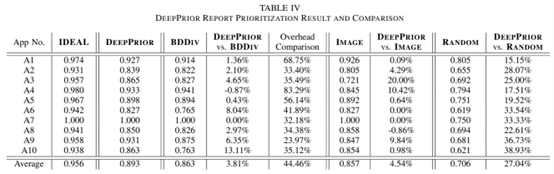
然后,我们将DEEPPRIOR与单一IMAGE策略的结果进行对比。DEEPPRIOR的平均提升幅度为4.54%,在2个应用(A3和A4)中,DEEPPRIOR的表现远超过了IMAGE策略。对于A8来说,DEEPPRIOR的策略弱于IMAGE策略。我们对A8的报告进行检查,发现是因为文本描述写的不好,不能对报告的优先级有积极的帮助。总的而言,结果证明了文本分析和深度图像理解两者结合的必要性,单一策略可以弥补彼此的缺点,提高确定优先级的准确性。
同时,我们还对DEEPPRIOR和BDDIV策略(即最先进的方法)进行了比较。根据实验结果,DEEPPRIOR的表现优于BDDIV,平均提升幅度为3.81%。在一些应用中的提升尤其明显。此外,我们还记录了从读取报告簇到输出优先级排序好的报告的总时间开销。结果显示,DEEPPRIOR所使用的时间不到BDDIV的一半,表现出极大的性能优势。
DEEPPRIOR相对于BDDIV的另一个优势是,DEEPPRIOR可以输出稳定的结果,而BDDIV的结果会浮动。根据BDDIV策略的详细结果(于在线包中),我们发现BDDIV的波动性很大。
在不同的应用上与基线策略相比的提升情况不同,可以用某些原因解释这一点。首先,“报告-种类”的比率是不同的,所以在一个应用的有限的activity集中,同样的activity重复出现的频率会变得很高。其次,不同的应用有不同的内容。比如A1是一款儿童教育类应用,它由大量的图片、视频、变体文字组成。在这种情况下,想要提取有用的文本信息,并对应用截图有一个全面的理解,就会变得更为复杂。因此,预估值会降低。
RQ3的结论:DEEPPRIOR对众测报告进行优先级排序的能力是非常优秀的,它的性能优于最先进方法BDDIV,但开销不到其一半。同时,IMAGE策略的具体实验也表明了我们深度截图理解算法的有效性。与最先进的方法相比,DEEPPRIOR的表现更加稳定。
E. 有效性风险
本次实验中应用的类别是有限的。我们的15个实验应用涵盖了8个不同的类别(根据应用商店分类法),类别覆盖有限。但是,我们要强调的是,由于我们对应用截图的深度理解涉及到对应用活动的布局特征,因此DEEPPRIOR仅适用于分析具有网格布局或列表布局的应用程序。我们所表述的也仅限于此类布局的应用中。
众包工人的注册不受限制。众包工人的能力不受限制,可能会出现低质量的报告。然而,即使一些报告的质量很低,如果它真的包含一个bug,DEEPPRIOR也可以识别它所描述的bug。如果没有,DEEPPRIOR会将该报告归类为单一类别,不会影响到其他报告的优先级。
我们构建的数据集是中文的。数据集的语言可能是一个威胁,但NLP和OCR技术相当强大。如果我们把文本处理引擎换成其它语言的引擎,文本处理也会很好地完成,不会对DEEPPRIOR产生负面影响。此外,机器翻译的成熟[16]也使其具备了处理跨语言文本信息的强大能力。
V. 相关工作
A. 众包测试
众包测试已是一种主流的测试方法。它与传统测试有很大的不同。测试任务被分配给大量来自不同地点、具备不同专业能力的众包工人。众包测试最显著的优势是能够模拟不同的使用条件,经济成本相对较低[17][18]。然而,众包测试的开放性导致了大量的冗余报告。关键问题是如何提高开发人员审核测试报告的效率。一些研究从选择有技能的众包工人来完成任务[19][20][21]。这样的策略是有效的,但同时它仍然难以控制,因为即使是熟练的众包工人也会在任务中偷懒。因此,我们认为在众包测试中,更重要的是处理测试报告,而非其他因素。Liu等[22]和Yu[6]分别提出了由测试报告的截图自动生成描述的方法,这些方法都基于这样的一个共识,即对所有众包工人而言,应用程序的截图容易获得,但文本描述很难编写。这一想法启发了我们对截图的深度理解,以帮助更好地确定测试报告的优先级。
B. 众包测试报告处理
为了更好地帮助开发人员审查报告和修复bug,当前已有许多研究来处理众包测试报告。基本策略包括报告分类、重复检测和报告优先级确定。在本节中,我们将介绍基于不同策略的相关工作。
Banerjee等人提出了FactorLCS[23],其使用常见的序列匹配,该方法在开放的bug跟踪库上是有效的。他们还提出了一种多标签分类器的方法[24],以找到报告集群中具有高度相似性的“主要”报告。同样,Jiang等人提出了TERFUR[14],这是一个使用NLP技术对测试报告进行聚类的工具,他们还过滤掉了低质量的报告。Wang等[25]将众包工人的特征作为测试报告的特征考虑进去,然后进行聚类。Wang等提出了LOAF[26],这是第一个将操作步骤和结果描述分开处理的报告特征提取方法。
更多的研究专注于检测重复测试报告。Sun等[27]采用信息检索模型,比较准确地检测重复的bug报告。Sureka等[28]采用基于字符n-gram的模型来完成重复检测任务。Prifti等[29]对大规模的开源项目测试报告进行了调查,提出了一种可以将重复报告的搜索集中在整个存储库的特定部分的方法。Sun等人提出了一个衡量相似度的检索函数REP[30],并且该函数包括部件、版本等非文本字段的相似度。Nguyen等提出了DBTM [31],该工具同时利用了基于IR的特征和基于主题的特征,并根据技术问题检测重复的bug报告。Alipour等[32]对测试报告上下文进行了较为全面的分析,提高了检测准确率。Hindle[33]通过结合上下文质量属性、架构术语和系统开发主题进行改进,提高了bug重复检测的能力。
上述方法,包括报告分类和重复检测,都是选择部分测试报告来代表所有的测试报告。但是,我们认为,即使存在重复的报告,所有的报告都包含有价值的信息。而且,在检测到重复的报告后,开发人员仍需要对报告进行审查,以推进bug的处理。因此,我们认为报告优先级是一个更好的选择。
当前也已有许多关于报告优先级的研究。Zhou等提出了BugSim[34],其考虑了文本和统计特征以对测试报告进行排序。Tian等[35]提出的DRONE是一种基于机器学习的方法,其考虑测试报告的不同因素来预测测试报告的优先级。Feng等人提出了一系列方法,DivRisk[36]和BDDiv[3],以对测试报告进行优先级排序,他们首先考虑了测试报告的截图。随后,Wang等[2]进一步研究并探索出了一种更加完善的测试报告优先级排序方法,并更提高了对截图的关注度。
在以上的所有研究中,只有少数研究,如[2]和[3],考虑了应用程序的截图,我们认为这是一个在提取特征来处理测试报告方面相当有价值的因素。但这些研究仅将截图作为简单的矩阵,而非有意义的内容。
C. 深度图像理解
图像理解是计算机视觉(CV)领域的一个热点问题。本节主要介绍在软件测试中利用图像理解的研究。
Lowe[10]提出了SIFT算法,其利用一系列新的图像局部特征,这些特征对于图像本身而言是恒定的,包括平移、缩放和旋转,以匹配目标图像上的特征点,并计算相似度。光学字符识别(Optical Character Recognition,OCR)是一种应用广泛的文字识别工具,它有助于根据图像上丰富的文字信息更好地理解图像。Nguyen等[37]提出了REMAUI,其使用CV技术来识别应用截图中的widget、文本、图像甚至容器。Moran等[38]在REMAUI的基础上提出了REDRAW,更精确地识别widget,并能自动生成应用UI的代码。同样,Chen等[39]也提出了一种结合CV技术和机器学习的工具,以根据应用截图生成GUI骨架。Yu等[1]提出了一种名为LIRAT的工具,可以在透彻了解应用截图的情况下跨平台记录和重新运行移动应用测试脚本。
VI. 结论
本文通过深度截图理解,提出了一种众包测试报告优先级排序方法DEEPPRIOR。DEEPPRIOR将应用截图和文本描述转化为四个不同的特征,包括问题widget、上下文widget、bug描述和复现步骤。然后,将特征汇总到DEEPFEATURE中,这些特征根据与bug的相关性,包括bug特征和上下文特征。之后,我们根据特征计算DEEPSIMILARITY。最后,根据DEEPSIMILARITY,按照预先设定的规则对报告进行优先级排序。我们还进行了一个实验来评估所提出的方法,结果显示,DEEPPRIOR的表现优于目前的最优方法,且开销不到它的一半。
感谢
本工作得到国家重点研发计划(2018AAA0102302)、国家自然科学基金(61802171、61772014、61690201)、中央高校基本科研基金(14380021)、国家大学生创新创业训练计划(202010284073Z)的部分支持。
参考文献
[1] S. Yu, C. Fang, Y. Feng, W. Zhao, and Z. Chen, “Lirat: Layout and image recognition driving automated mobile testing of cross-platform,” in 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2019, pp. 1066–1069.
[2] J. Wang, M. Li, S. Wang, T. Menzies, and Q. Wang, “Images don’t lie: Duplicate crowdtesting reports detection with screenshot information,” Information and Software Technology, vol. 110, pp. 139–155, 2019.
[3] Y. Feng, J. A. Jones, Z. Chen, and C. Fang, “Multi-objective test report prioritization using image understanding,” in 2016 31st IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2016, pp. 202–213.
[4] N. O’Mahony, S. Campbell, A. Carvalho, S. Harapanahalli, G. V. Hernandez, L. Krpalkova, D. Riordan, and J. Walsh, “Deep learning vs. traditional computer vision,” in Science and Information Conference. Springer, 2019, pp. 128–144.
[5] X. Xiao, X. Wang, Z. Cao, H. Wang, and P. Gao, “Iconintent: automatic identification of sensitive ui widgets based on icon classification for android apps,” in 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 2019, pp. 257–268.
[6] S. Yu, “Crowdsourced report generation via bug screenshot understanding,” in 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2019, pp. 1277–1279.
[7] Y. Kim, “Convolutional neural networks for sentence classification,” arXiv preprint arXiv:1408.5882, 2014.
[8] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Advances in neural information processing systems, 2013, pp. 3111–3119.
[9] L. R. Rabiner, “A tutorial on hidden markov models and selected applications in speech recognition,” Proceedings of the IEEE, vol. 77, no. 2, pp. 257–286, 1989.
[10] D. G. Lowe et al., “Object recognition from local scale-invariant features.” in iccv, vol. 99, no. 2, 1999, pp. 1150–1157.
[11] M. Muja and D. G. Lowe, “Fast approximate nearest neighbors with automatic algorithm configuration.” VISAPP (1), vol. 2, no. 331-340, p. 2, 2009.
[12] D. F. Silva and G. E. Batista, “Speeding up all-pairwise dynamic time warping matrix calculation,” in Proceedings of the 2016 SIAM International Conference on Data Mining. SIAM, 2016, pp. 837–845.
[13] T. Y. Chen, F.-C. Kuo, R. G. Merkel, and T. Tse, “Adaptive random testing: The art of test case diversity,” Journal of Systems and Software, vol. 83, no. 1, pp. 60–66, 2010.
[14] B. Jiang, Z. Zhang, W. K. Chan, and T. Tse, “Adaptive random test case prioritization,” in 2009 IEEE/ACM International Conference on Automated Software Engineering. IEEE, 2009, pp. 233–244.
[15] G. Rothermel, R. H. Untch, C. Chu, and M. J. Harrold, “Prioritizing test cases for regression testing,” IEEE Transactions on software engineering, vol. 27, no. 10, pp. 929–948, 2001.
[16] S. Karimi, F. Scholer, and A. Turpin, “Machine transliteration survey,” ACM Computing Surveys (CSUR), vol. 43, no. 3, pp. 1–46, 2011.
[17] R. Gao, Y. Wang, Y. Feng, Z. Chen, and W. E. Wong, “Successes, challenges, and rethinking–an industrial investigation on crowdsourced mobile application testing,” Empirical Software Engineering, vol. 24, no. 2, pp. 537–561, 2019.
[18] K. Mao, L. Capra, M. Harman, and Y. Jia, “A survey of the use of crowdsourcing in software engineering,” Journal of Systems and Software, vol. 126, pp. 57–84, 2017.
[19] Q. Cui, S. Wang, J. Wang, Y. Hu, Q. Wang, and M. Li, “Multi-objective crowd worker selection in crowdsourced testing.”
[20] Q. Cui, J. Wang, G. Yang, M. Xie, Q. Wang, and M. Li, “Who should be selected to perform a task in crowdsourced testing?” in 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), vol. 1. IEEE, 2017, pp. 75–84.
[21] M. Xie, Q. Wang, G. Yang, and M. Li, “Cocoon: Crowdsourced testing quality maximization under context coverage constraint,” in 2017 IEEE 28th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2017, pp. 316–327.
[22] D. Liu, X. Zhang, Y. Feng, and J. A. Jones, “Generating descriptions for screenshots to assist crowdsourced testing,” in 2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 2018, pp. 492–496.
[23] S. Banerjee, B. Cukic, and D. Adjeroh, “Automated duplicate bug report classification using subsequence matching,” in 2012 IEEE 14th International Symposium on High-Assurance Systems Engineering. IEEE, 2012, pp. 74–81.
[24] S. Banerjee, Z. Syed, J. Helmick, and B. Cukic, “A fusion approach for classifying duplicate problem reports,” in 2013 IEEE 24th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2013, pp. 208–217.
[25] J. Wang, Q. Cui, Q. Wang, and S. Wang, “Towards effectively test report classification to assist crowdsourced testing,” in Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, 2016, pp. 1–10.
[26] J. Wang, S. Wang, Q. Cui, and Q. Wang, “Local-based active classification of test report to assist crowdsourced testing,” in Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, 2016, pp. 190–201.
[27] C. Sun, D. Lo, X. Wang, J. Jiang, and S.-C. Khoo, “A discriminative model approach for accurate duplicate bug report retrieval,” in Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering-Volume 1, 2010, pp. 45–54.
[28] A. Sureka and P. Jalote, “Detecting duplicate bug report using character n-gram-based features,” in 2010 Asia Pacific Software Engineering Conference. IEEE, 2010, pp. 366–374.
[29] T. Prifti, S. Banerjee, and B. Cukic, “Detecting bug duplicate reports through local references,” in Proceedings of the 7th International Conference on Predictive Models in Software Engineering, 2011.
[30] C. Sun, D. Lo, S.-C. Khoo, and J. Jiang, “Towards more accurate retrieval of duplicate bug reports,” in 2011 26th IEEE/ACM International Conference on Automated Software Engineering (ASE 2011). IEEE, 2011, pp. 253–262.
[31] A. T. Nguyen, T. T. Nguyen, T. N. Nguyen, D. Lo, and C. Sun, “Duplicate bug report detection with a combination of information retrieval and topic modeling,” in 2012 Proceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering. IEEE, 2012, pp. 70–79.
[32] A. Alipour, A. Hindle, and E. Stroulia, “A contextual approach towards more accurate duplicate bug report detection,” in 2013 10th Working Conference on Mining Software Repositories (MSR). IEEE, 2013, pp. 183–192.
[33] A. Hindle, A. Alipour, and E. Stroulia, “A contextual approach towards more accurate duplicate bug report detection and ranking,” Empirical Software Engineering, vol. 21, no. 2, pp. 368–410, 2016.
[34] J. Zhou and H. Zhang, “Learning to rank duplicate bug reports,” in Proceedings of the 21st ACM international conference on Information and knowledge management, 2012, pp. 852–861.
[35] Y. Tian, D. Lo, and C. Sun, “Drone: Predicting priority of reported bugs by multi-factor analysis,” in 2013 IEEE International Conference on Software Maintenance. IEEE, 2013, pp. 200–209.
[36] Y. Feng, Z. Chen, J. A. Jones, C. Fang, and B. Xu, “Test report prioritization to assist crowdsourced testing,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, 2015, pp. 225–236.
[37] T. A. Nguyen and C. Csallner, “Reverse engineering mobile application user interfaces with remaui (t),” in IEEE/ACM International Conference on Automated Software Engineering, 2016.
[38] K. Moran, C. Bernal-Cardenas, M. Curcio, R. Bonett, and D. Poshy- ´ vanyk, “Machine learning-based prototyping of graphical user interfaces for mobile apps,” arXiv preprint arXiv:1802.02312, 2018.
[39] C. Chen, T. Su, G. Meng, Z. Xing, and Y. Liu, “From ui design image to gui skeleton: a neural machine translator to bootstrap mobile gui implementation,” in Proceedings of the 40th International Conference on Software Engineering. ACM, 2018, pp. 665–676.