
知识图谱加强神经机器翻译
引用
Zhao Y , Zhang J , Zhou Y , et al. Knowledge Graphs Enhanced Neural Machine Translation[C]// Twenty-Ninth International Joint Conference on Artificial Intelligence and Seventeenth Pacific Rim International Conference on Artificial Intelligence {IJCAI-PRICAI-20. 2020.
摘要
知识图谱(Knowledge graphs, KG)存储了大量关于各种实体的结构化信息,其中许多是神经机器翻译(neural machine translation, NMT)的平行句对所未覆盖的。为提高这些实体的翻译质量,在本文中我们提出了一种新颖的知识图谱加强神经机器翻译方法。具体来说,我们首先通过将源知识图谱和目标知识图谱转换为统一的语义空间,以归纳这些实体的新翻译结果。然后我们生成足够的伪平行句对,其中包含这些归纳实体对。最后,NMT模型由原始句和伪句对联合训练。对汉英和英日翻译任务的大量实验表明,我们的方法在翻译质量方面明显优于强基线模型,尤其是在处理归纳实体方面。
介绍
基于编码器-解码器的神经机器翻译(NMT)因其分布式表示与端到端的学习而成为一种最新、最先进的方法。
在翻译过程中,句子中的实体起着重要的作用,它们的正确翻译会很大程度上影响整个句子的翻译质量。因此,优于实体的重要性,人们提出了各种方法以改善翻译。其中,有一种方法旨在结合知识图谱(KG)来改善实体翻译。
在许多语言和领域中,人们构建各种大规模KG来组织实体的结构化知识。同时,一些研究将KG纳入NMT,以增强句对数据集中的实体的语义表示并改进翻译。然而,这些研究只关注同时出现在 KG和训练句对数据集中的实体(我们将这种实体称为K+D实体)。实际上,除了这些K+D实体之外,KG还包含许多未出现在训练句对数据集中的实体(我们将这种实体称为K-D实体)。而这些K-D实体在之前的研究中都被忽略了。
在本文中,我们认为这些K-D实体严重损害了翻译质量,而知识图谱可以缓解这一问题。图1显示了一个例子,假设可以从汉英平行句中提取两个翻译对,即“asipilin-aspirin”和”yaopin-drug”。同时,源实体”yixianshuiyangsuan”是一个K-D实体,没有出现在平行句对中。虽然我们可以归纳这个实体被翻译成“aspirin”,但这是从源三元组“(asipilin,alias,yixianshuiyangsuan)”表明,”yixianshuiyangsuan”是”asipilin”的别称而得来的。
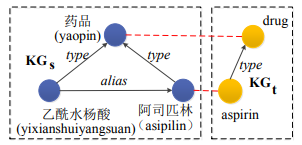
图1 表明非平行KG也可归纳K-D实体的翻译结果的示例。在示例中,可以提取两个翻译对:“asipilin-aspirin”和”yaopin-drug”(如红色虚线所示)。虽然实体”yixianshuiyangsuan”是一个K-D实体,但它可能被翻译成”asipilin”,因为源三元组“(asipilin,alias,yixianshuiyangsuan)”表明,”yixianshuiyangsuan”是”asipilin”的别称。
因此,本文中,我们提出了一个有效的方法,将非平行的源和目标KG纳入NMT系统。在KG的帮助下,所提出的方法可以使NMT学习包含K-D实体的新实体翻译对。更具体而言,方法包含三个步骤。1)双语K-D实体归纳:该步骤中,我们首先从短语翻译表中提取种子对。然后,我们通过最小化种子对中源实体和目标实体之间的距离,将源和目标 KG 转换为统一的语义空间。最后我们在这个语义空间下归纳出K-D实体的翻译结果。2)伪平行句对生成:我们生成足够的、包含归纳出的实体对的伪平行句对。3)联合训练:在这一步我们通过原始句和伪句对联合训练NMT模型,使NMT能够学习归纳翻译对中源实体和目标实体之间的映射。汉英和英日翻译任务的大量实验表明,我们的方法在翻译质量上明显优于强基线模型,特别是在处理归纳K-D实体方面。
我们主要有如下贡献:
* 我们提出一种方法,将非平行的KG纳入NMT模型。
* 我们设计了一个新颖的方法,用KG归纳K-D实体翻译的结果,生成伪平行句对,促进NMT对K-D实体做出更好的预测。
问题定义
本文中,我们使用以下三种数据资源来训练一个NMT模型θ。
\1) 平行句对D={(X, Y)},其中X代表源句。Y表示目标句。
\2) 原KG 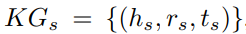 ,其中hs,ts和rs分别代表头实体,尾实体和源语言的关系。
,其中hs,ts和rs分别代表头实体,尾实体和源语言的关系。
3)目标KG 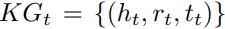 ,其中ht,tt和rt分别代表头实体,尾实体和目标语言的关系。
,其中ht,tt和rt分别代表头实体,尾实体和目标语言的关系。
由于平行的KG很难获得,本位置,KGs和KGt不是平行的,同时,我们假设KGs和KGt包含许多未出现在平行句对D的实体,我们称这些实体为K-D实体。K-D实体集O可形式上定义为:
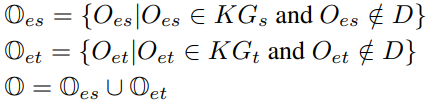
其中Oes和Oet分别代表K-D源实体和目标实体。
我们认为,尽管句对D可能不包含这些K-D实体的翻译知识,但KG可以帮助归纳它们的翻译结果。因此,我们在本文中的目标是在KGs和KGt的帮助下提高这些K-D实体的翻译质量。
方法描述
图2展示了我们提出的方法的框架,其包括三步:1)双语K-D实体归纳,2)伪句对生成,3)联合训练。接下来我们将在下面小节中介绍每个步骤。
双语K-D实体归纳
本步中,我们希望能归纳出K-D实体的翻译结果。为了实现该目标,我们的主要思想是将源和目标KG转化为一个统一的语义空间,然后在该语义空间下归纳这些实体的翻译结果。
具体而言,算法1展示了我们的双语K-D实体归纳方法,该方法首先需要做四个准备工作(第1-4行)。我们首先将KGs和KGt分别表示为实体嵌入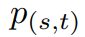 是翻译概率(第3行)。最后的准备工作是通过公式(3)提取K-D实体集O。在图2的例子中,有三个K-D实体”yixianshuiyangsuan”、”purexintong”和”paracetamol”。其中前两个是K-D源实体,最后一个是K-D目标实体。
是翻译概率(第3行)。最后的准备工作是通过公式(3)提取K-D实体集O。在图2的例子中,有三个K-D实体”yixianshuiyangsuan”、”purexintong”和”paracetamol”。其中前两个是K-D源实体,最后一个是K-D目标实体。
有了上述准备,我们现在需要构建种子对集S(第5-8行)。如果有一个短语翻译对 中。在图2的例子中,两个短语对“(yaopin,drug,0.4)”和“(asipilin,aspirin,0,9)”被选入种子对中。
中。在图2的例子中,两个短语对“(yaopin,drug,0.4)”和“(asipilin,aspirin,0,9)”被选入种子对中。
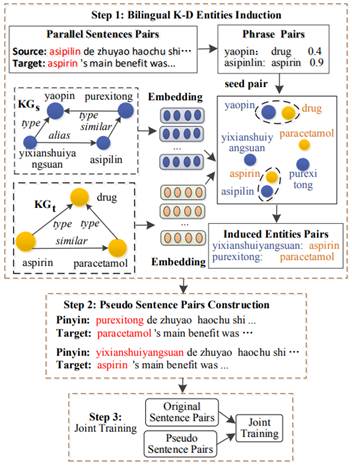
图2 所提出的将非平行KG纳入NMT的方法。
得到的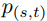 。如果一个种子对的概率较大,这个种子对在损失函数中的权重也较大。因此,损失函数可以定义为公式(4)(第9行)。
。如果一个种子对的概率较大,这个种子对在损失函数中的权重也较大。因此,损失函数可以定义为公式(4)(第9行)。

最后的任务是归纳K-D实体的翻译结果(第10-17行)。给定一个K-D源实体 中(第16-17行)。在图2的例子中,我们归纳了两个新的配对:“(yixianshuiyangsuan,aspirin)”和”(purexintong,paracetamol)”。现在,集合
中(第16-17行)。在图2的例子中,我们归纳了两个新的配对:“(yixianshuiyangsuan,aspirin)”和”(purexintong,paracetamol)”。现在,集合
包含所有新的归纳翻译对。
伪句对的生成
现在我们的目标是生成包含归纳实体对的句对。其主要思想是将种子对的上下文转移到与该种子对接近的归纳对。具体来说,如果一个归纳对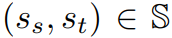 之间的距离低于预定的超参数λ,如下所示:
之间的距离低于预定的超参数λ,如下所示:
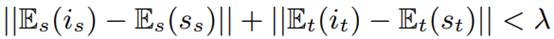
我们希望将种子对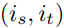 。
。
在图2的例子中,假设归纳对“(yixianshuiyangsuan,aspirin)”和“(purexitong,paracetamol)”都接近种子对“(asipilin,aspirin)”,我们用这两个归纳对替换“(asipilin,aspirin)” ,得到如图2中间部分所示的伪句对。
联合训练
最后的任务是用原始平行句对D和伪平行句对Dp训练NMT模型θ。我们的实验表明,伪句对Dp的数量明显少于原始句对D。为了克服这个不平衡的问题,我们首先对伪句对Dp进行n次超采样,并通过以下方式设计损失函数:
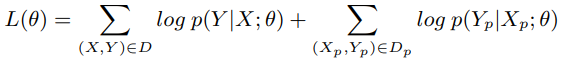
其中,前者是来自原始数据D的损失,后者是来自超采样的伪数据Dp的损失。
试验设置
我们在汉译英(CN⇒EN)和英译日(EN⇒JA)的翻译任务中测试了所提出的方法。CN⇒EN的平行句对是从LDC语料库中提取的,该语料库包含了201万个句对。在CN⇒EN任务中,我们利用了三个不同的KG:i) 医学KG,其中源KG包含38万个三元组,目标KG包含23万个三元组,这些三元组是从YAGO中筛选出来的。我们构建了2000个医疗句对作为开发集,2000个医疗句对作为测试集。目标KG包含28万个三元组,这些三元组也是从YAGO中过滤出来的。我们还构建了2000个关于旅游的句对作为开发集,以及2000个其他句对作为测试集。我们选择NIST03作为开发集,NIST 04-06作为测试集。使用KFTT数据集作为EN⇒JA平行句对。源和目标KG是DBP15K。训练对和KG的统计数据见表1。
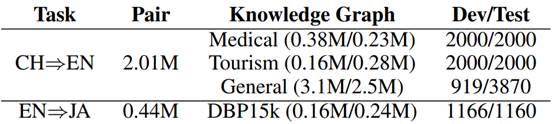
表1 训练数据的统计。Pair列显示了平行句对的数量,Knowledge Graph列显示了三元组的名称和数量(源/目标)。Dev/Test列显示了开发/测试集的句子数量。
我们实现了基于THUMT工具包的NMT模型和基于openKE工具包的知识嵌入方法。我们使用 Transformer 模型的“基本”版本参数。在所有的翻译任务中,我们使用BPE方法来合并30000次。我们用不区分大小写的BLEU来评估最终的翻译质量。
在这种方法中,我们比较了以下 NMT 系统:
\1) RNMT:使用两个LSTM层作为编码器和解码器的基线NMT系统。
\2) Transformer:最先进的NMT系统,具有自注意力机制。
\3) Transformer+RC:这是一种通过添加句子中实体间的关系约束来合并KG的方法,其目标是在句对中获得K+D实体的更好表示。
4)Transformer/RNMT+KG:这是我们在Transformer和RNMT的基础上提出的KG增强型NMT模型,其中我们将超参数δ(算法1)设置为0.45(医学)、0.47(旅游)、0.39(一般)和0.43(DBP15K),λ(4.2节)设置为0.86(医学)、0.82(旅游)、0.73(一般)和0.82(DBP15K)。超采样时间n(第4.3节)分别被设定为4(医疗)、3(旅游)、2(一般)和3(DBP15K)。所有这些超参数都在开发集中进行了微调。
实验结果
翻译结果
RNMT模型的结果。表2列出了CN⇒EN和EN⇒JA翻译任务的主要翻译结果。我们首先将我们的方法与RNMT进行比较。比较第1行和第4-6行,提出的RNMT+KG在所有测试集上都比RNMT有所提升。具体来说,当使用医疗、旅游和一般KG时,所提出的方法可以分别比RNMT多出1.29(12.54对11.25)、0.88(12.77对11.89)和0.55(41.89对41.34)BLEU点。同时,在EN⇒JA的翻译任务上,提升可以达到0.48个BLEU点(27.91对27.43)。
Transformer 模型的结果。我们在Transformer的基础上进行了实验来评估所提出的方法。如第2行和第7-9行所示,我们的方法也可以提高Transformer上的翻译质量,在这三个KG的帮助下,其改进可以分别达到1.12(15.69对14.57),0.90(14.88对13.98)和0.51(44.91对44.40)BLEU点。此外,在EN⇒JA翻译任务中,提议的Transformer+KG可以比Transformer多出0.60个BLEU点(30.10对29.50)。
不同嵌入方法的结果。我们也对利用不同的知识嵌入方法时的结果感兴趣。在这里,我们测试了以下三种知识嵌入方法。TransE、TransD和TransR。从结果(第4-9行)中,我们可以看到,在所有的任务中,这三种知识嵌入方法可以达到相似的BLEU分数。
Transformer+RC对比我们的方法。我们还将所提出的方法与Transformer+RC(第3行)进行比较。结果显示,我们提出的方法(第7-9行)比Transformer+RC分别多出0.90(15.69对14.79)、0.77(14.88对14.11)、0.08(44.91对44.83)和0.27(30.10对29.83)BLEU点。结果显示了我们所提出方法的优点。更重要的是,在Transformer+RC的基础上,我们的方法(第10行)可以进一步提高翻译质量,说明Transformer+RC仍然面临K-D实体的问题,而我们的方法可以缓解这个问题。
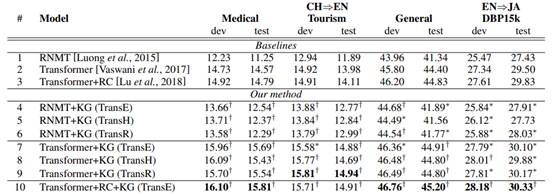
表2 不同方法在 CN⇒EN 和 EN⇒JA 翻译任务上的 BLEU 分数。 “*”表示提出的系统在统计上比基线系统更好(p < 0.05),“†”表示 p < 0.01。
超参数的影响
在算法1中,我们设置了一个预定义的超参数δ来确定双语归纳对。表3显示了不同δ下的BLEU分数(医用KG)。我们可以看到,当δ=0.45时,BLEU分数是最大的。当δ超过0.45时,BLEU分数(dev)从15.96下降到14.94。
同时,我们也对归纳的双语K-D实体的精确度感到好奇。因此,我们随机选择了300个不同δ下的归纳双语实体翻译对,并手动分析其正确率。结果也报告在表3中(列Precison)。从结果中我们可以看出,随着超参数δ的增加,可以归纳出更多的K-D实体翻译对,而精度则从43.1%下降到13.7%。这些结果表明,有必要在K-D实体翻译对的数量和精度之间找到平衡。
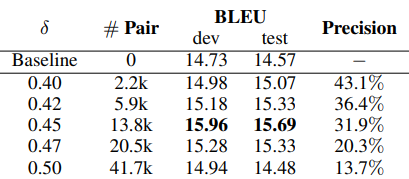
表3:不同δ下的BLEU分数。#对显示了归纳的K-D双语实体对的数量。Precison表示归纳的K-D双语实体对的正确率。
我们设置了一个预先定义的超参数λ来生成伪句对。图3显示了结果(医学KG),其中x轴表示超参数λ,y轴表示开发集和测试集的BLEU分数。图中的数字表示伪句对的数量。从结果中我们可以看出,随着超参数λ的增加,可以生成更多的伪句对。当λ=0.86时,BLEU分数(dev)变得最大。我们认为原因在于,当λ变得过大时,伪句对可能包含更多的噪声,从而损害最终的翻译质量。
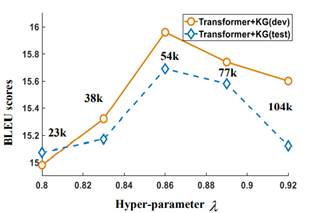
图3 超参数λ的影响,其中x轴表示超参数λ,y轴表示开发集和测试集的BLEU分数。当λ=0.86时,开发集和测试集的BLEU分数最大。
K-D实体的分析
本文中,我们的目标是用KG增强NMT的K-D实体。因此,我们也分析了所提方法在K-D实体上的结果。分析是在句子层面和实体层面进行的。
在句子层面的分析上,我们将测试句子分为两个不同的部分:i)带有K-D实体的句子(send w K-D)和ii)不带K-D实体的句子(send w/o K-D)。表4报告了实验结果。从结果中,我们可以看到,我们提出的方法对没有K-D实体的句子影响不大。但它可以将带有 K-D 实体的句子分别从 9.96 显著提高到 11.75 BLEU 点(RNMT)和从 13.46 显著提高到15.15 BLEU 点(Transformer)。结果表明,我们提出的方法可以在含有K-D实体的句子上产生更好的翻译结果。
我们还分析了在单词层面上归纳K-D实体的结果。具体来说,我们随机选取了300个句子(医疗KG),其中包含162个K-D实体(267次)和72个K+D实体(96次)。我们计算以下三个值:1)归纳的K-D实体的正确率(次);2)未归纳的K-D实体的正确率(次);3)K+D实体的正确率(次)。统计结果见表5。从结果可以看出,Transformer+RC可以将K+D实体的翻译正确率(次)从36.5%(35)提高到43.8%(42)。而我们的方法对归纳K-D实体最为有效,它将翻译正确率(次)从21.5%(31)提高到31.3%(45)。更重要的是,当结合Transformer+RC和我们的方法时,RC+Ours都能将归纳的K-D和K+D分别提高到31.9%(46)和46.9%(45),这说明我们的方法和Transformer+RC是互补的。
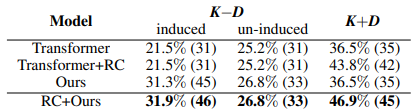
表5 K-D和K+D实体的正确率(次)。
图4显示了我们所提出的方法可以改善归纳K-D实体的翻译。在这个例子中,涉及到的K-D实体 “yixianshuiyangsuan”被Transformer完全翻译成错误的目标短语。而提出的Transformer+KG可以克服这个错误,产生正确的翻译结果 “asipirin”。

图4表明所提出的方法可以改进归纳K-D实体的例子。
结论
为了解决NMT中的K-D实体,我们提出了一种知识图谱增强的NMT方法。我们首先通过利用非平行KG归纳K-D实体的翻译结果,然后生成伪平行句对,最后联合训练NMT模型。在汉译英和英译日任务上的大量实验表明,我们的方法在翻译质量上明显优于基线模型,特别是在处理归纳K-D实体方面。