
DeepInspect:深度神经网络的黑盒木马检测与缓解框架
引用
Chen H, Fu C, Zhao J, et al. DeepInspect: A Black-box Trojan Detection and Mitigation Framework for Deep Neural Networks[C]//IJCAI. 2019: 4658-4664.
摘要
深度神经网络 (DNN) 容易受到神经木马 (NT) 攻击。在神经木马攻击中,攻击者在DNN训练期间注入恶意行为。这种类型的“后门”攻击在输入标记有被攻击者指定的触发器(trigger)段时激活,其会导致模型预测错误。由于DNN在各关键领域中被广泛应用,因此在使用模型之前检测预训练的DNN是否感染木马是必不可少的操作。我们在本文中的目标是解决对未知DNN的NT攻击的安全问题,确保安全的模型部署。我们提出了DeepInspect,这是第一个具有最小的模型先验知识的黑盒木马检测解决方案。DeepInspect使用条件生成模型从查询的模型中学习潜在触发器的概率分布,从而检索出后门插入的足迹。除了NT检测之外,我们还表明DeepInspect的触发器生成器能够通过模型修补来有效缓解木马感染。我们证实了DeepInspect对各种基准的最先进的NT攻击的有效性、效率和可扩展性。广泛的实验表明,DeepInspect提供了卓越的检测性能和比以前的工作更低的运行时间开销。
介绍
深度神经网络(DNN)已被证明了其卓越的性能,其被越来越多地应用于各关键应用中,包括人脸识别、生物医学诊断、自动驾驶等。由于训练一个高精度的DNN很耗费时间和资源,客户常常从目前供应链中的第三方获得预训练的深度学习(DL)模型。Caffe Model Zoo是一个向用户公开分享预训练模型的平台样例。DNN训练的不透明性为攻击者打开了一个安全漏洞,使得他们可以通过干扰训练过程插入恶意行为。在推理阶段,任何带有触发器的输入数据都会被受感染的DNN错误分类为攻击目标。例如,如果触发器被添加到输入的“右转”标志上,则木马模型预测“左转”。
这种类型的神经木马(NT)攻击(也称为 “后门 “攻击)已在之前的工作中被发现,其具有两个关键特性:(i)有效性:带有触发器的输入被高概率地预测为攻击目标;(ii)隐蔽性:插入的后门对合法输入(即输入中没有触发器)保持隐蔽。这两个特性使NT攻击具有威胁性,并且难以检测。现有的研究侧重于确定输入是否包含假设查询模型已被感染的触发器(即“输入的健全性检查”)。
由于以下挑战,检测未知 DNN 的木马攻击很困难:(C1) 后门的隐蔽性使得它们难以通过功能测试(以测试准确性作为检测标准)来识别;(C2)在木马检测过程中仅能获取有限的有关查询模型的信息。干净的训练数据集或黄金参考模型在实际环境中可能不可获得。训练数据包含用户的个人信息,因此通常不会与预训练的DNN一起发布。(C3)攻击者指定的攻击目标对防御者来说是未知的。此处攻击者是恶意模型提供者,而防御者是终端用户。攻击者目标的这种不确定性使 NT 检测变得复杂,因为对于具有众多输出类别的大规模模型而言,暴力搜索所有可能的攻击目标是不切实际的。
据我们所知,Neural Cleanse是现有的唯一针对检查DNN对后门攻击的脆弱性的工作。然而,NC提出的后门检测方法依赖于干净的训练数据集,其中不包含任何恶意操纵的数据点。由于原始训练数据的私有性,这种假设限制了他们方法的应用场景。为了应对这些挑战(C1-C3),我们提出了DeepInspect,这是第一个实用的木马检测框架,其可根据最少的查询模型信息,确定DNN是否已经被后门注入(即“预训练模型的健全性检查”)。DeepInspect(DI)包括三个主要步骤:模型反转以恢复替代训练数据集,使用条件生成对抗网络(cGAN)进行触发器重建,以及基于统计假设检验的异常检测。本文的技术贡献总结如下:
* 启用 DNN 的神经木马检测。我们提出了第一个后门检测框架,该框架无需干净的训练数据或正确参考模型的帮助即可检查预训练 DNN 的安全性。我们的威胁模型所做的最小假设确保了DeepInspect的广泛适用性。
* 在各种DNN基准上对 DeepInspect 进行综合评估。我们进行了大量实验来证实DeepInspect的功效、效率和可扩展性。我们证明DeepInspect与之前的NT检测方案相比,明显更为可靠。
* 提出了一种新型的木马缓解模型修补方案。DeepInspect的条件生成模型所恢复的触发器揭示了被查询模型的敏感性。我们表明,防御者可以利用触发器生成器进行对抗训练并使插入的后门失效。
DeepInspect框架
木马检测概述
DeepInspect背后的关键直觉如图1所示。木马插入的过程可以被认为是在合法的数据点附近添加多余的数据点,并将其标记为攻击目标。从原始数据点到恶意数据点的移动即是后门攻击中使用的触发器。作为木马插入的结果,我们可以从图1中观察到,将合法数据转化为属于攻击目标的样本所需的扰动与相应的良性模型中的扰动相比要小。DeepInspect识别这种“小”触发器的存在,例如木马插入留下的“足迹”,并恢复潜在触发器以提取扰动统计信息。
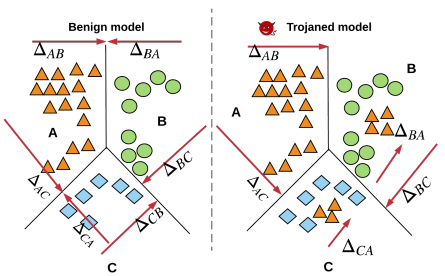
图1 DeepInspect木马检测背后的直觉。在这里,我们考虑三分类问题。定义∆AB表示将A类中的所有数据样本转移到B类所需的扰动,∆A表示将所有其他类中的数据点转移到A类的扰动:∆A=max(∆BA, ∆CA)。一个具有攻击目标A的木马模型满足∆A<<∆B, ∆C,而在良性模型中,这三个值之间的差异较小。
图2说明了DeepInspect的整体框架。DI首先采用了模型反转(Model Inversion, MI)方法,生成一个包含所有类别的替代训练数据集。然后,训练一个条件GAN来生成可能的木马触发器,将被查询的模型部署为固定的判别器D。为了反向设计木马触发器,DI构建了一个条件生成器G(z, t),其中z是一个随机噪声向量,t是目标类。G被训练来学习触发器的分布,即,被查询的DNN应在反向数据样本x和G的输出的叠加上预测攻击目标t。最后,恢复的触发器的扰动等级(变化幅度)被用作异常检测的测试统计数据。我们基于假设测试的木马检测是可行的,因为其探索了后门插入的内在“足迹”。

图2 DeepInspect框架的全局流图。
威胁模型
DeepInspect以最小的假设检验被查询的DNN对NT攻击的敏感性,从而解决上一节提到的有限信息(C2)的挑战。更具体地说,我们假设防御者对所查询的DNN具有以下知识:输入数据的维度、输出类别的数量以及给定任意输入查询的模型的置信度分数。此外,我们假设攻击者有能力将任意类型和比例的毒害数据注入训练集,以达到其所期望的攻击成功率。我们强大的威胁模型确保了DeepInspect在现实世界环境中的实际使用有效,而前人的工作需要一个良性的数据集来协助后门检测。
DeepInspect方法
DeepInspect框架由三个主要步骤组成。(i)模型反转:防御者首先在被查询的DNN上应用模型反转,以恢复一个覆盖所有输出类别的替代训练数据集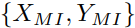 。恢复的数据集在下一步被GAN训练使用,以解决挑战C2;(ii)触发器生成。DI利用生成模型来重构木马攻击所使用的可能的触发器模式。由于攻击目标(受感染的输出类)对防御者来说是未知的(C3),我们采用一个条件生成器,有效构建属于不同攻击目标的触发器;(iii)异常检测:在使用cGAN为所有输出类生成触发器后,DI 将木马检测定义为一个异常检测问题。收集所有类别的扰动统计数据,左尾概率的异常表明后门的存在。
。恢复的数据集在下一步被GAN训练使用,以解决挑战C2;(ii)触发器生成。DI利用生成模型来重构木马攻击所使用的可能的触发器模式。由于攻击目标(受感染的输出类)对防御者来说是未知的(C3),我们采用一个条件生成器,有效构建属于不同攻击目标的触发器;(iii)异常检测:在使用cGAN为所有输出类生成触发器后,DI 将木马检测定义为一个异常检测问题。收集所有类别的扰动统计数据,左尾概率的异常表明后门的存在。
模型反转
回顾一下,我们的威胁模型假设在木马检测过程中没法获得干净的训练数据集。因此,我们采用模型反转来恢复一个替代训练集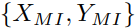 ,在下一步协助生成器训练。已有研究证明了数据可以从预训练的模型中提取,并将模型反转表述为一个优化问题。MI的目标函数如式(1)所示,通过GD进行迭代最小化。
,在下一步协助生成器训练。已有研究证明了数据可以从预训练的模型中提取,并将模型反转表述为一个优化问题。MI的目标函数如式(1)所示,通过GD进行迭代最小化。
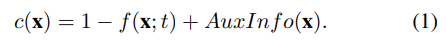
这里,x是输入数据,t是要恢复的目标类,f是查询模型在给定x作为其输入的情况下预测t的概率,AuxInfo(x) 是包含对输入的辅助约束的可选项。
触发器生成
DeepInspect的关键思想是训练一个条件发生器,学习木马触发器的概率密度分布(probability density distribution, pdf),其扰动等级用以检测统计。特别地,DI采用cGAN来“模拟”木马攻击的过程:D(x+G(z, t))=t。这里,D是被查询的DNN,t是被检查的攻击目标,x是由MI获得的数据分布的样本,而触发器是条件发生器∆=G(z, t)的输出。请注意,现有的使用固定触发器模式的攻击可以被认为是触发器分布为常值的特殊情况。
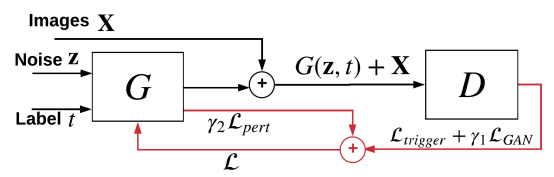
图3 DeepInspect的条件GAN训练示意图。
图3显示了我们的触发器生成器的高层概述。回顾一下,DeepInspect将预先训练好的模型部署为固定的判别器D。因此,触发器生成的关键是制定损失函数来训练条件发生器。由于我们的威胁模型假设输入维度和输出类别的数量对防御者来说是已知的,他可以找到一个可行的G的拓扑结构,产生的触发器∆与反转输入x的形状一致。为了模仿木马攻击,DI首先加入了公式(2)所示的负对数似然损失(nll)来量化G的输出触发器的质量,以欺骗预训练模型D:
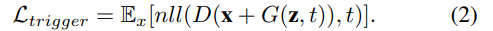
此外,还集成了一个常规的对抗损失项,以确保“假”图像xt=x+G(z,t)不能与原始图像用判别器D区分开:
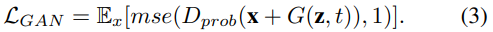
这里,mse表示”均方误差”损失函数。最后,我们通过在其l1范数上添加一个合页损失来限制G的输出量:
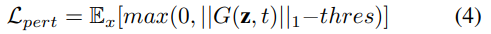
对扰动幅度进行约束是稳定GAN训练的常见做法。上述三种损失的加权和被用来训练条件G。
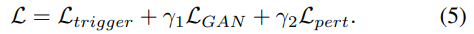
我们选择超参数γ1、γ2以确保G的输出触发器达到至少95%的攻击成功率。我们认为DeepInspect可以在黑盒环境下运行,因为我们的触发器恢复过程不需要任何关于模型内部的信息。
异常检测
DeepInspect探讨了这样的观察结果:与木马模型中其他未受感染的类相比,人们可以发现目标类的扰动等级异常小的触发器。在第二步中使用经过训练的生成器为每个类生成触发器后,DI 进行假设检验和鲁棒统计来检测触发器扰动中异常值的存在。更具体地说,我们使用”双中值绝对偏差”(DMAD)的一个变体作为检测标准。我们的DMAD方案首先计算出所有测试统计点S的中位数m,并使用它来分割触发器扰动的原始列表。然后计算左子组Sleft中所有数据点与组中位数的绝对偏差,将其表示为dev_left。总体偏差和一致性常数(正态分布为 1.4826)的乘积表示为 mad。
我们将数据点的“偏差因子(deviation factor, df)”定义为中位数的绝对偏差与MAD值之间的比率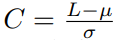 遵循标准正态分布N(0,1)。显著性等级α和截止阈值c之间的关系描述如下:
遵循标准正态分布N(0,1)。显著性等级α和截止阈值c之间的关系描述如下:
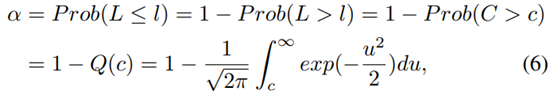
其中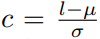 。DI利用DMAD来估计群体的标准σ,并用样本的中位数来代替平均值μ。因此,归一化的RV C可用于对偏差因子进行建模,这意味着从公式(6)中得到的阈值c也适用于具有相同显着性等级α的df。DI通过允许防御者指定公式(6)中使用的显著性等级来提供可调整的检测性能。
。DI利用DMAD来估计群体的标准σ,并用样本的中位数来代替平均值μ。因此,归一化的RV C可用于对偏差因子进行建模,这意味着从公式(6)中得到的阈值c也适用于具有相同显着性等级α的df。DI通过允许防御者指定公式(6)中使用的显著性等级来提供可调整的检测性能。
评估
我们进行了大量实验来研究DeepInspect在各种基准测试中的性能。我们对先前的工作和检测开销分析进行了定量比较。
实验设置
我们针对两种最先进的木马攻击评估DeepInspect。
我们首先评估DI在BadNets中提出的后门插入方法的性能。触发器是图像右下角的一个白色方块。后门是通过使用操纵集和其余干净数据集这两者的混合来训练模型以实现嵌入的。我们在MNIST和GTSRB基准上进行BadNets攻击。我们还评估了TrojanNN攻击下的DI。Liu等设计了一个特定的触发器,将目标DNN中选定的神经元刺激到高激活值,而不是硬编码重新标记部分修改后的训练数据。我们分别在它们的开源代码在VGGFace 2和ResNet-18上进行带有方形和水印触发器的TrojanNN攻击。
在我们的实验中,我们在原始训练数据集中加入了~10%的操纵数据,以使我们使用BadNets攻击方法获得的所有木马基准测试达到95%以上的木马激活率。表1总结了上述两种木马攻击的设置和结果。
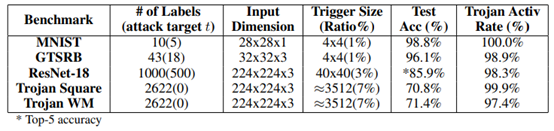
表1 评估的木马攻击的总结。展示后门注入的设置和结果。
每个木马检测实验重复10次,本节中报告对应平均指标。为了验证DeepInspect的异常检测的可行性,我们测量了良性模型和木马模型的偏差因子,并在图4(a)中展示了结果。如果其偏差因子大于截止阈值,则确定查询模型被“感染”。使用α=0.05的显著性等级(对应于截止阈值c=2),如图4(a)所示,DI对所有受感染模型得出df>2,对所有良性模型得出df<2。因此,DI通过在所有基准测试中实现0%的假阳性率和0%的假阴性率,满足了”有效性”标准。
被感染的DNN和相应的良性DNN之间偏差因子的巨大差距表明,df是木马检测的有效指标。为了证实DI所使用的关键直觉(如图1所示),我们测量了DI的条件生成器所恢复的触发器的扰动等级,并在图4 (b)中可视化了它们的分布。可以观察到,受感染标签(用三角形表示)的扰动幅度远小于未受感染的类,因此其可在我们的检测中通过鲁棒的统计数据来使用。此外,与NC相比,我们为未感染标签恢复的测试统计量的分布具有更小的离散性,这表明我们产生了更可靠的检测结果。
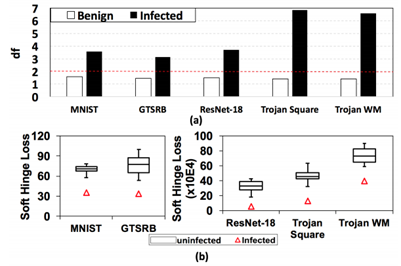
图4 (a) DeepInspect恢复的良性和木马模型的触发器的偏差因子。红色虚线表示显著性等级α=0.05的决策阈值。(b)木马模型中对被感染和未被感染的标签生成的触发器的扰动等级(l1范数上的合页损失)。
接下来,我们比较了DeepInspect和Neural Cleanse在不同环境下的检测性能。由于NC假设有干净的数据集,我们在与DI相同的模型反转过程中得到的反转数据集上执行他们提出的检测方法,以确保两者的公平比较。
对触发器大小的敏感性
攻击者使用的触发器的大小会影响DI和NC的检测性能,因为它会影响测试统计数据。更具体地说,DI利用恢复的触发器的合页损失作为统计数据,而NC使用l1范数作为决策标准。这里,我们在GTSRB基准上使用不同大小的方形触发器,并如图5所示比较两种方法的检测性能。可以看到,NC在大小为2×2、12×12和16×16的触发器上产生了三个假阴性报告。此外,NC的偏差因子随着触发器大小的增加呈现出下降的趋势,这表明检测统计量对触发器大小很敏感。DI在所有基准中都没有产生假阴性,因此与NC相比,它对触发器大小的增加不太敏感。在MNIST基准上也观察到类似的趋势。
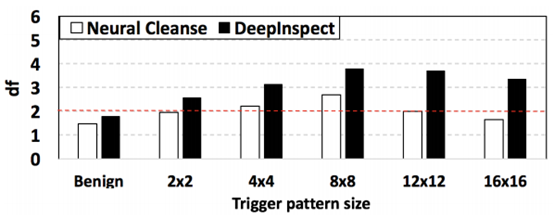
表5 木马检测对触发器大小的敏感性分析。图中显示了感染各种方形触发器的GTSRB基准上的DeepInspect和Neural Cleanse的偏差因子。红色虚线表示木马检测的截止阈值。
对木马目标数量的敏感性
我们在上一节中评估了DI在单目标木马攻击上的表现。此处,我们考虑一种更高级的后门攻击,即使用同一触发器感染多个输出类别。我们将这种类型的攻击命名为“多目标”木马。更具体地说,触发器标记的每个输入的目标标签t是从一组类T中随机选择的。如果模型的预测属于攻击目标集T,则认为后门被激活。我们使用BadNets中的木马插入方法,对MNIST基准进行单/多目标后门攻击。受感染模型达到了与未受感染基线相当的测试准确率和高于98%的木马激活率。图6显示了DI和NC对攻击目标标签数量(表示为|T|)的敏感性。NC在所有三个多目标木马基准上都会表现出假阴性情况,而当|T|=3和5时,DI 在查询模型中成功检测到木马。
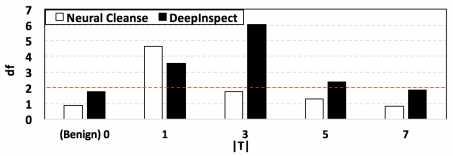
图6 木马检测对攻击目标数量的敏感度分析。DeepInspect 和 Neural Cleanse 在各种单/多目标木马攻击设置中的偏差因子是在MNIST基准上测量的,触发器的大小为4×4。
开销分析
我们评估了DI的运行时开销,并在此与之前的工作进行比较。回顾一下,DI利用一个条件生成器来同时恢复属于多个类别的触发模式。此外,我们证明DI可以结合自动编码器来加速大型基准测试中的木马检测。相反,NC使用GD来单独搜索每个目标类中的触发器。NC与自动编码器不兼容,因为它分别恢复了二维掩码和三维触发器模式。
图 7 显示了DI和NC之间的总体相对运行时间比较。我们在具有8GiB内存的Nvidia RTX2080 GPU上实现这两种检测方法,并在模型反演过程中在每个类别中恢复5张图像。MI整个过程的运行时间可如图7示计算出来。经验结果显示,在MNIST(N = 10)和GTSRB(N = 43)基准上,NC比DI分别快1.7倍和1.2倍。然而,DI在ResNet-18(N = 1000)和VGGFace基准(N = 2622,在图7中表示为 “Trojan Square”和 “Trojan WM”)上比NC快5.3倍和9.7倍。可以看出,与NC相比,我们的框架在大型基准上速度更快。因此,DI的特点是在真实环境中,对具有诸多输出类别的DNN,具有更好的效率和可扩展性。
讨论
让我们考虑木马插入过程中使用的源类和目标类的数量,目前的DI解决了多对一/多对多的情况。DeepInspect可以很容易地扩展到检测具有不同机制的其他木马攻击。一个白盒自适应攻击者可以战略性地选择源类和目标类,使得误分类所需的扰动幅度不会明显小于其他未受影响的类。这种攻击可能会以降低效率为代价来降低 df。通过评估每个源-目标类对的所需扰动,DI可以被调整为检测干净标签攻击。我们评估了木马检测期间干净数据集可用时的DI,表明了DI的性能与NC相当。
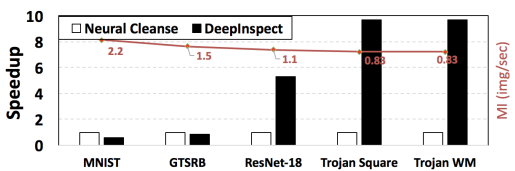
图7 与Neural Cleanse相比,DeepInspect的研究增速。自动编码器和MI的训练时间包含在DI何NC的运行时间中。橙色虚线表示模型反转的吞吐量(每秒的图像数)。与NC相比,DI在大型基准测试中表现出了更好的可扩展性。
通过模型修补的木马缓解
回顾一下,DeepInspect通过训练一个条件生成器来学习潜在触发器的pdf,从而有效地检测出后门攻击的发生。换句话说,一旦我们完成了G的训练,我们就有了一个能够为任何目标类构建不同触发模式的生成模型。因此,DeepInspect的生成器促进了 “对抗学习”,
可用于提高良性模型的鲁棒性,或“修补”受感染的DNN以阻止木马攻击。
在这里,我们展示了DeepInspect如何被用作补救方案,以减轻已确定的目标类t的木马攻击。我们通过用反转训练集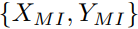 来构建补丁集。将另外10%的反转数据作为验证集,以寻找再训练配置(如batch大小、学习率等)。最后,根据数据应用中的原始损失,对受感染模型进行10个epoch的对抗训练。
来构建补丁集。将另外10%的反转数据作为验证集,以寻找再训练配置(如batch大小、学习率等)。最后,根据数据应用中的原始损失,对受感染模型进行10个epoch的对抗训练。
表2总结了DeepInspect在没有干净数据下的对各种受感染的DNN上进行模型修补的结果。可以看到,我们的木马缓解方案有效地降低了嵌入式触发器的激活率,同时保持了模型在正常数据集上的性能。修补后的模型的偏差因子小于DeepInspect异常检测中使用的截止阈值c=2,因此能够通过模型鲁棒性检查并安全部署。我们想强调的是,假设干净的数据是可获得的,那么修补后的TAR可以进一步降低到~3%。
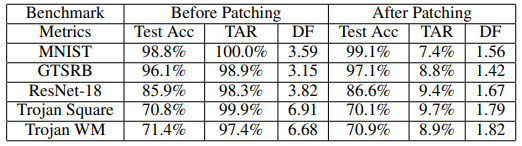
表2 对DeepInspect木马缓解方案的评估。在进行模型修补后,木马激活率(TAR)有效降低,测试准确率得以保留。
结论和未来的工作
我们提出了DeepInspect,这是在深度学习领域中第一个实用的木马检测和缓解方案,其对被查询模型的先验知识需求最小。DeepInspect将预先训练好的DNN作为其输入,并对模型的合理性返回一个二元结果(良性的/被木马注入的)。与之前依靠干净数据集进行木马检测的工作不同,DeepInspect只需要对被查询的DNN进行黑盒访问,就能重建潜在的木马触发器。DeepInspect利用条件生成模型,同时学习多个攻击目标的触发器的概率分布。我们基于假设检验的异常检测允许防御者通过指定截止阈值来平衡检测率和误报率。我们针对两种最先进的木马攻击,对DeepInspect进行了大量的评估,以证实其与之前的工作相比具有高检测率和低误报率。除了卓越的后门检测性能外,DeepInspect的条件触发器生成器还支持有效的木马缓解解决方案,即使用对抗训练修补模型。
我们在这里讨论两个未来的研究方向。DeepInspect可以进行调整,以提高对更复杂的木马攻击(如大尺寸触发器和多目标后门)的检测性能。对于多目标木马攻击,可以修改损失定义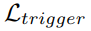 ,以允许在G训练期间给定相同的操纵输入的多个目标类。此外,可以通过结合更高级的GAN训练策略来优化DI触发器恢复的运行时间。
,以允许在G训练期间给定相同的操纵输入的多个目标类。此外,可以通过结合更高级的GAN训练策略来优化DI触发器恢复的运行时间。